Agent 系列之记忆系统
引言
在上一篇《Agent 系列之上下文工程》中,我们讨论了单次长任务中 Token 爆满的“生存问题”。本篇我们将视线拉长,探讨 Agent 如何跨越会话周期,通过记忆系统实现认知沉淀。
一个典型场景(Typical Scenarios):
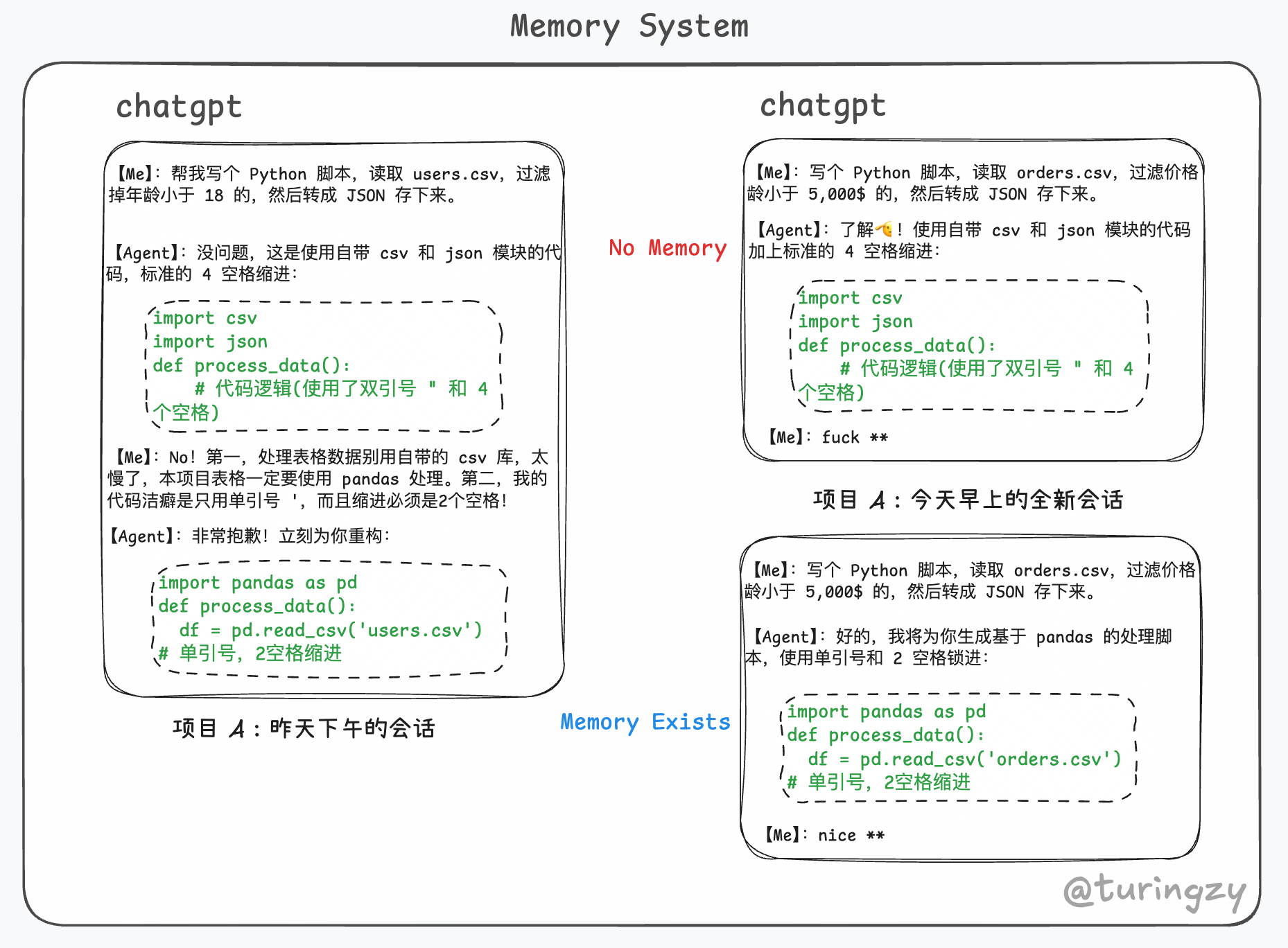
有无记忆系统的使用体验一目了然。我们不可能在一个会话里完成所有任务,在新会话中如果对于同一类问题仍多次交流才能得到正确回答,无疑是一个非常费心费力的过程。
因此,如果你希望构建一个具备高可用性与成长性的 AI Agent,完备的记忆系统是 Harness Engineering 中必不可缺的底层基础设施。
还是以 Claude Code(后文简称“CC”)的记忆系统为讲解对象,这里主要通过两条链路和几个关键机制进行学习。
六维记忆体系
以下内容和图片主要来自对视频 【Claude Code 的记忆机制到底强在哪?】 的总结。
CC 的记忆体系可能不完全适合你的业务 Agent,但却给我们提供了一个极佳的参考方向。
CC 设计了一个六维记忆金字塔,如下图所示:

- 指令记忆:系统的底层基石与出厂设置,包含绝对遵守的系统规则和项目全局规范(如
CLAUDE.md),不随对话改变。 - 短期记忆:当前的实时上下文窗口,记录未经压缩的原始对话与操作历史,精度最高但存在 Token 容量上限。
- 工作记忆:执行复杂任务时的“草稿本”,实时记录当前步骤进度、目标偏移情况和下一步预判,防止长任务中途迷失方向。
- 长期记忆:跨会话的持久化知识库(系统最核心部分),以文件形式(如
memdir)沉淀关键知识,如用户偏好、行为纠正/确认、项目上下文、外部指针。绝对不记架构、文件路径、Git 历史、调试方案等代码的“副本”。 - 摘要记忆:长会话的核心内容压缩包,在后台将海量的历史对话提炼为关键摘要(Session Memory),突破短期记忆的容量瓶颈。
- 休眠重塑:离线或空闲状态下的后台“大脑清理”机制(AutoDream),自动合并相似记忆、清理过时垃圾,优化整个记忆网络的结构。
用户输入的每一句话都会进入短期记忆;遇到复杂问题它会用到工作记忆打草稿;聊得太久它会自动生成摘要记忆;有价值的核心结论会被沉淀为长期记忆;整个过程都在指令记忆的监督下进行;并在下班后通过休眠重塑来整理归档。
记忆的写入链路
对于记忆的“写”链路,这里可以关注三个核心环节:“何时触发、谁来执行、如何保存”。
长期记忆:意图驱动与双步写入
CC 的长期记忆(跨会话)的写链路,完全由用户意图驱动。在交互的过程中,如果用户明确下达指令(或模型敏锐识别出某些信息具有长期保留价值,比如用户规定的代码架构或特定偏好),它会直接将保存记忆作为当前规划的一部分。
由于不需要依赖任何硬性的字数或轮次限制,负责执行的主 Agent 会主动调用系统预置的本地文件读写工具。
在具体落盘时,系统严格执行双步写入法:
主 Agent 会先在专用目录下创建或更新一个包含详细知识的具体 Markdown 正文文件;随后退回根目录,在名为 MEMORY.md 的总索引文件中追加一条简短的描述和指向该正文的链接,从而完成持久化知识的结构化建档。
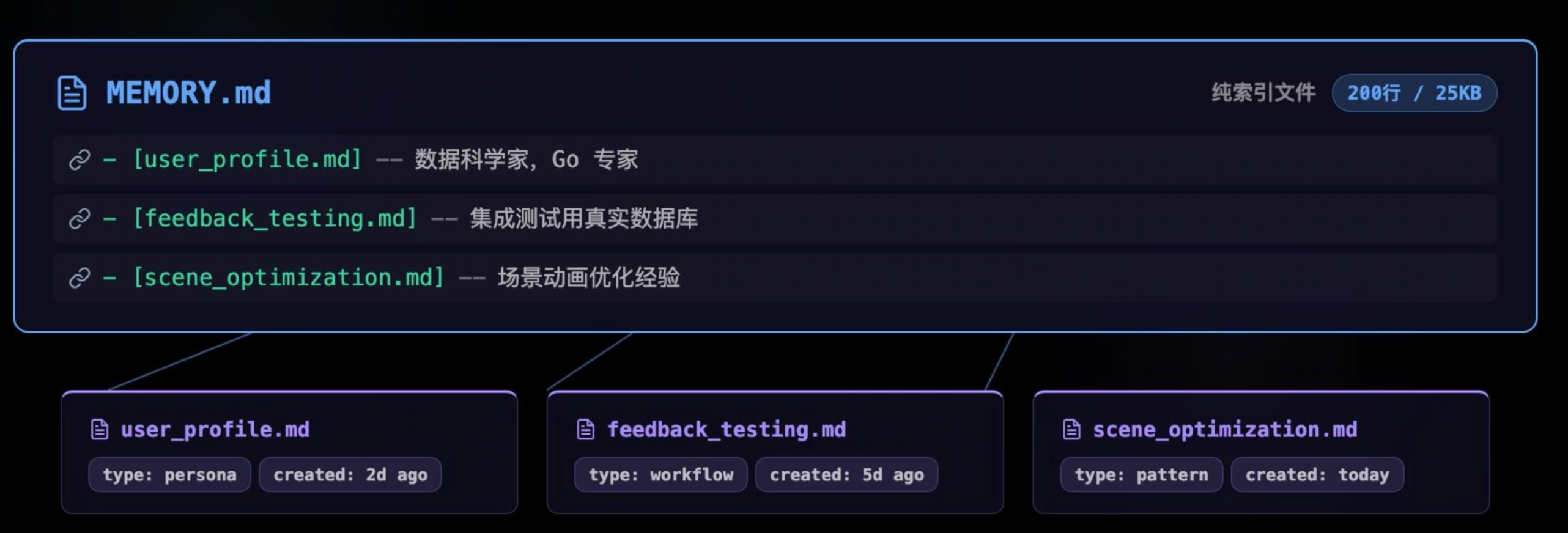
摘要记忆:被动触发与静默压缩
相比之下,摘要记忆(长会话)的写入链路则完全遵循一套被动且严格的客观工程逻辑。
它的触发依赖于双重硬性阈值与自然断点:只有当会话累积超过一万个 Token、期间发生至少三次工具调用,且当前轮次处于没有连续调用工具的自然对话停顿点时,系统才会启动这一流程。
为了不阻塞主 Agent 与用户的实时聊天,系统主 Agent 会在察觉阈值到达后,通过底层钩子在后台静默拉起一个专门的 SubAgent。由这个后台执行者负责通读海量历史并提炼出摘要。
最终,这段包含当前代码上下文与敏感对话隐私的压缩内容,会被写入一个专属的单文件中,并被系统赋予读写的最高级别隔离权限,以此在保证响应速度的同时兼顾物理级的极高安全性。

记忆的读取链路
在面临“海量记忆文件”与“有限大模型上下文”的核心矛盾时,CC 摒弃了传统的全量加载策略,也未采用关键词匹配、向量检索等,而是设计了一套由“轻量模型”驱动的、高度拟人化的三阶段读取链路。
异步预取 (PreFetch) —— 轻量级元数据扫描
为了不阻塞主程序的对话响应,读链路的第一步是在后台异步执行的。系统不会强行加载所有记忆文件的正文,而是快速遍历整个记忆目录,仅提取每个文件的元数据(如文件名称、类型和摘要描述)。
这一步通过极低成本的本地文件系统 I/O 操作,为系统构建了一份轻量级的全局元数据清单(Metadata Manifest),作为后续模型筛选的数据基础。

旁路筛选 (Side Query) —— LLM 驱动的智能过滤
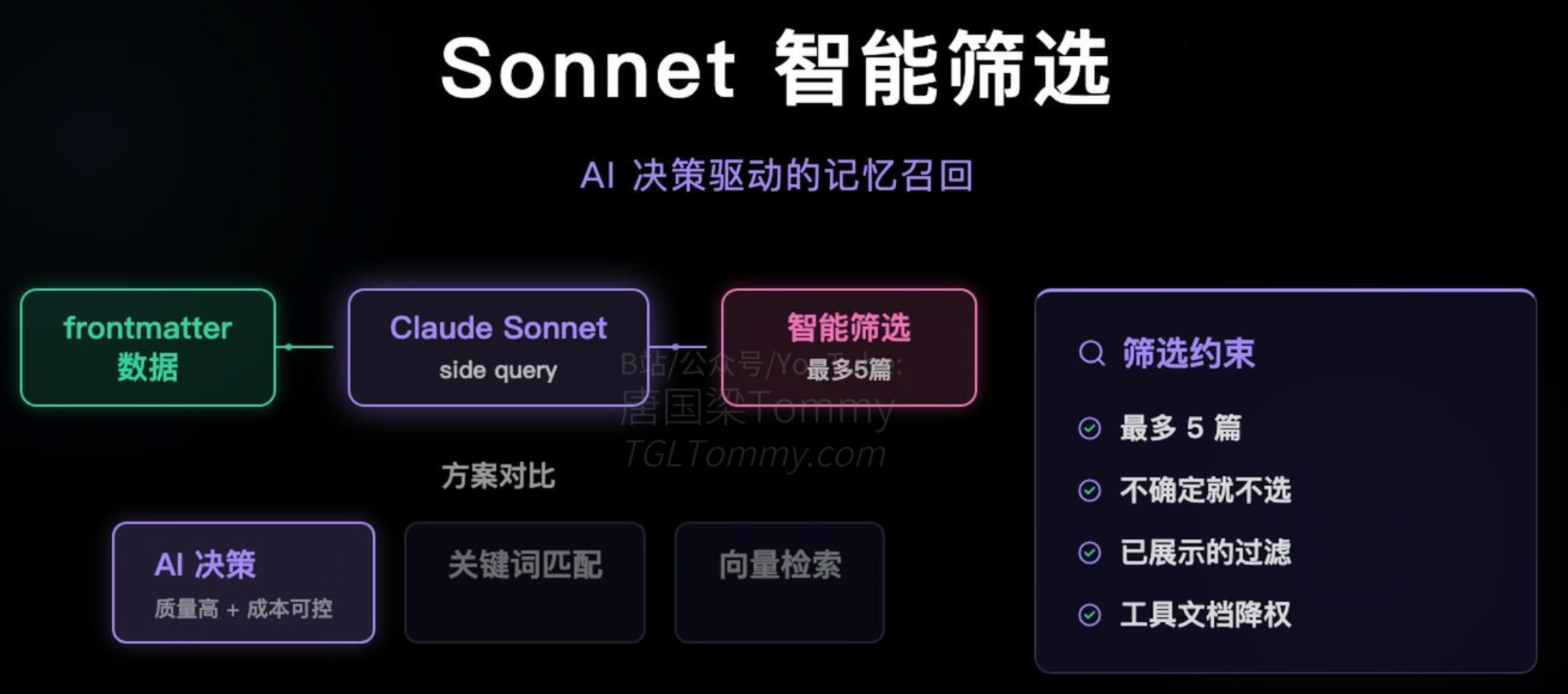
获取元数据清单后,系统并没有使用基于关键词或向量相似度的传统检索,而是将筛选权交给了大模型自身(通常调用速度更快的小尺寸模型,如 Claude Sonnet 作为旁路)。
系统将这份“元数据清单”与当前对话的上下文一并交给旁路模型,让其根据四大核心约束进行精准的逻辑判断:
- 强相关优先:基于深层语义理解,寻找对当前任务真正有价值的历史信息。
- 不确定则弃:奉行宁缺毋滥原则,避免引入无关噪音。
- 已展示去重:自动过滤本轮已在上下文中的文件,防止冗余。
- 工具文档降权:避免与当前高优先级的系统级工具说明抢占上下文权重。
经过这层严苛的逻辑过滤,系统最多只会选出 5 个最相关的记忆文件,将其完整正文回灌给主 Agent。
新鲜度验证 (Freshness Check) —— 防信息陈旧污染
这是确保记忆质量的最后一道防线。对于最终被选中的记忆文件,系统会以自然语言的形式,在 Prompt 中为其打上时间戳和“陈旧警告”。
这使得主 Agent 在阅读历史记忆时具备了状态感知能力 —— 在使用旧的架构规定或代码逻辑时,模型会被明确提醒需结合当前最新的代码现状进行验证,从而阻断了陈旧记忆对当前决策的污染。

读写调度与防冲突机制
对于记忆的提取与写入,系统必须解决并发耗时和进程冲突的问题。CC 在这里做了两个非常重要的工程实现:
两回合策略 (Two-Turn Strategy)
两回合策略是针对文件修改工具在底层执行层面的一项极致并发优化。
因为大模型修改现有记忆文件存在破坏原有内容的风险,所以“写”之前必须先“读”。为了避免陷入低效且极占上下文的串行读写(读 A 写 A -> 读 B 写 B),该策略强行将分散的操作压缩为两个高度并行的标准回合:
- 第一回合:统一并发读取所有需要操作的目标文件。
- 第二回合:在全局消化内容后,统一并发写回更新的结果。
这种以并发换轮次的设计,大幅降低了多轮 API 的网络交互耗时,并保证了长任务记忆修改的精准度。

读写互斥锁 (Read-Write Mutex)
读写互斥机制是 CC 记忆架构中,为了协调前台主 Agent 与后台 SubAgent 工作重叠而设计的高阶防冲突与防冗余机制。它的核心运作逻辑类似于操作系统中的“互斥锁”。
在实际的长会话场景中,当用户明确下达指令要求主 Agent 记录下某个关键任务、规范或结论时,主 Agent 会主动调用文件工具将这些高价值信息沉淀到持久化记忆中,同时在当前的对话进度中留下一个“已归档”的游标标记。
随后,当负责长会话压缩的后台子 Agent 因为 Token 积攒达到阈值而被唤醒时,它不会立刻盲目地开始总结。它会先去探测这个标记,一旦检测到近期上下文已经被主 Agent 盖过“已处理”的标记,子 Agent 会直接触发 SKIP 逻辑,将进度游标推移,不再对这段记录进行重复阅读和摘要。
相反,只有在主 Agent 埋头干活、没有产生持久化记忆的空白对话区间,子 Agent 才会正常触发 EXTRACT 任务来进行信息提取。

休眠重塑机制 (AutoDream)
AutoDream 是 CC 记忆架构中对抗系统长期“熵增”的终极垃圾回收与复盘整理机制。
由于全局扫描、语义去重和合并索引是一项极其消耗 API 算力与系统耗时的重型操作,系统为其设定了极为严苛的离线批处理触发阈值:“距离上次整理必须超过 24 小时,且期间必须有至少 5 个不同的会话产生了新记忆。“
这种设计巧妙地模拟了人类的“睡眠期”,确保高昂的维护成本只在知识碎片积累到一定量级、产生冗余冲突概率足够高时才被支出,绝不抢占用户高强度写代码时的实时交互资源。


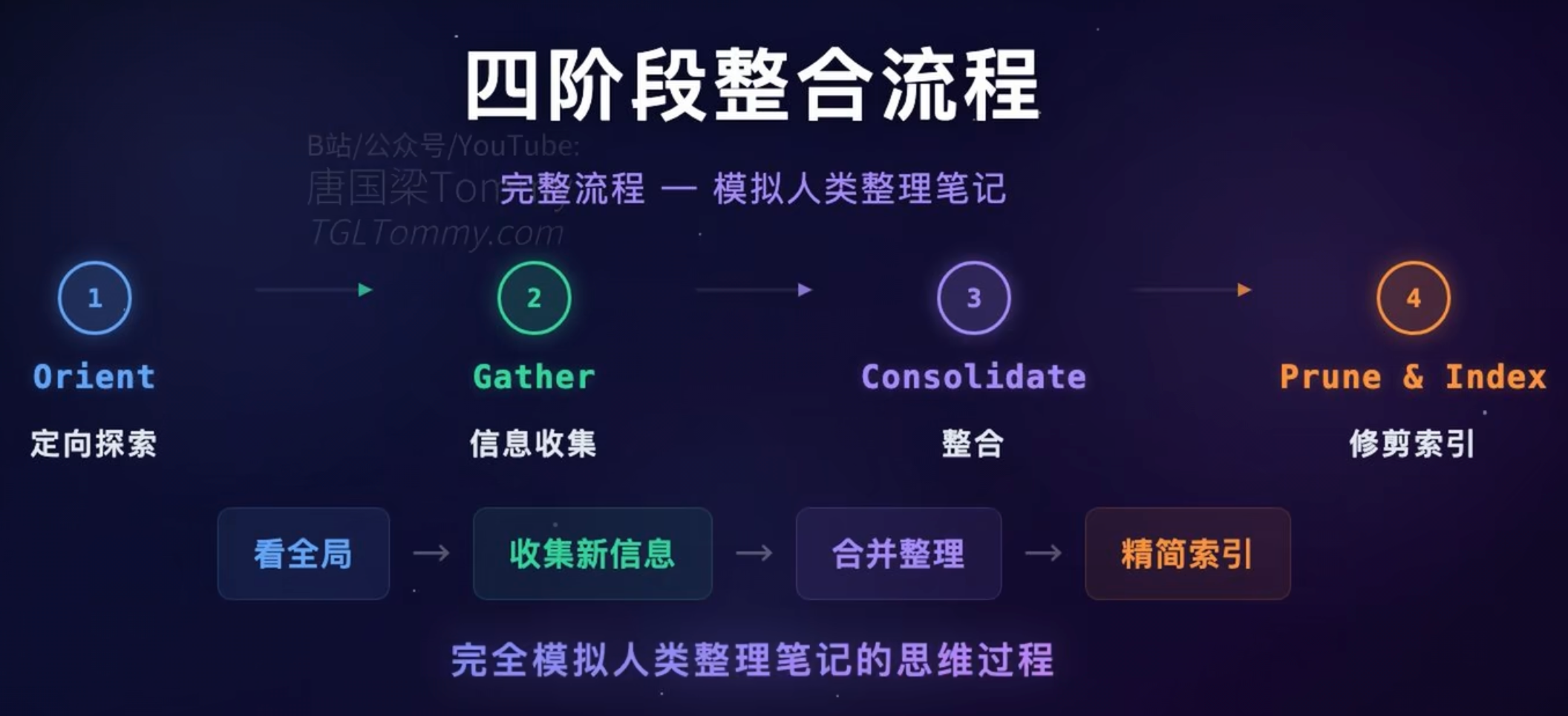
在具体执行层面,一旦满足触发条件,系统会在后台唤醒全局盘点流程。大模型会化身为“图书管理员”,通读现有的记忆库文件并进行智能的“合并同类项”:
- 它会自动识别并融合各个会话中碎步快跑产生的重合记录,化解前后矛盾的逻辑(例如新旧架构规范的更替)。
- 在物理层面直接删除那些过时、无用的 Markdown 碎片文件。
- 清理完具体正文后,该机制会执行最关键的一环:重构总索引
MEMORY.md。它会将庞杂的条目重新压缩提炼,强行将其拉回 200 行或 25KB 的硬性死线之内。
扩展
OpenClaw
OpenClaw 是一款开源的个人 AI 助手,支持通过 Telegram、微信、QQ 等主流社交平台进行交互。其记忆体系采用了极简的三层文件结构,均存储于 Agent 工作区:
- 长期记忆 (
MEMORY.md): 存储用户偏好与核心决定。在每次私聊(Direct Message)会话开始时加载,作为 Agent 的“性格底色”。 - 日记记忆 (
memory/YYYY-MM-DD.md):记录当日的工作笔记、观察结果、会话摘要及原始上下文。系统默认加载“今天+昨天”的记忆以保持连贯性。随着时间推移,有价值的信息会被提炼至长期记忆,过时信息则会被清理。 - 梦境记忆 (
DREAMS.md):由后台执行的 Dreaming 机制 产生。Agent 会在空闲时回顾日常对话,提取高价值信息并写入长期记忆,实现知识的内化。
OpenClaw 的设计哲学是 “Human-readable”(人类可读),所有记忆都是 Markdown,方便用户手动纠偏。
Hermes Agent
Hermes Agent(由 Nous Research 开发)是一款自学习型 AI Agent,其核心理念是 “The agent that grows with you”。
Hermes Agent 的记忆体系分为三层:
- 内建文件记忆(Built-in File Memory):
MEMORY.md(Agent 自画像)与USER.md(用户画像)在会话开始时被加载为冻结快照,注入系统提示词。 - 会话持久记忆(Session Persistence):基于 SQLite 数据库(使用 WAL 模式提高读写效率),通过
FTS5虚拟表实现对历史对话的全文搜索。 - 外部记忆(External Memory):可选项,支持 Honcho、Mem0、Hindsight 等八种主流记忆组件。其中 Honcho 提供的“辩证式用户建模”是其特色。
在 Hermes 架构中最硬核、也最值得在 Agent 架构设计中参考的一点是闭环学习与技能转化 (Closed Learning Loop & Skill Synthesis)。
例如,当你指导 Hermes 完成一个复杂的 Hadoop 集群日志抓取任务后,它会回溯该任务的原始链路(Raw Trace)。一旦识别出这是一个成功的高价值路径,它会自动调用代码生成能力,将这套解决逻辑封装成一个 Skill。下次遇到类似需求,它不再去回想以前的记忆,而是直接调用这个自创的 Skill。
八种记忆组件差异
| Provider | 核心能力 | 差异化 |
|---|---|---|
| Honcho | 辩证 Q&A + peer cards + 语义搜索 + 结论持久化 | 最丰富的用户建模 |
| Mem0 | LLM 事实提取 + 语义搜索 + 重排 | 最简集成路径 |
| Hindsight | 知识图谱 + 实体解析 + 多策略检索 | 最强结构化推理 |
| Holographic | HRR 代数 + 信任评分 + 实体解析 | 零外部依赖 |
| RetainDB | 持久知识库 + Delta 压缩 | 存储效率 |
| Supermemory | 语义搜索 + 多容器 + 会话末尾摘要摄取 | 细粒度容器管理 |
| ByteRover | 层级知识树 + 模糊搜索 + LLM 策展 | 本地优先层级知识管理 |
| OpenViking | 双向上下文 + 语义检索 + URI 层级浏览 | URI 层级知识导航 |
深入了解查阅官网,快速了解看 Agent Memory项目工程级横向对比(上) 和 Agent Memory项目工程级横向对比(下)。
参考
- 唐国梁Tommy. Bilibili. Claude Code 的记忆机制到底强在哪?六维记忆体系深度解析,一节视频讲透指令记忆、长期记忆、Session Memory 与 AutoDream. 2026
- openclaw. Github(openclaw). OpenClaw
- openclaw. Github(openclaw). openclaw 记忆体系
- NousResearch. Github(hermes-agent). Hermes Agent
- NousResearch. NousResearch
- 唐国梁Tommy. Bilibili. Agent Memory项目工程级横向对比(上). 2026
- 唐国梁Tommy. Bilibili. Agent Memory项目工程级横向对比(下). 2026