Agent 系列之反馈与反思
引言
在 Harness Engineering 中为 Agent 构建系统 化反馈与深度反思机制是非常有必要的。反馈让 Agent 可以知道用户的真实诉求,反思让 Agent 提升自己的能力,而不是原地踏步。
需要注意的是,反馈与反思本身并不会改变底层模型的智力,但能显著提升 Agent 的工程能力。
下面我们来看几个业界头部产品的实践案例:
1、 Gemini 的每次回答用户都可以通过赞/踩来进行反馈。
2、爆火的 Hermes Agent 的一个核心机制就是其内置自我学习循环。
3、Agents Need Feedback Loops, Not Perfect Prompts Warp 公司发表的一篇工程博客,主要说了他们开发的 AI 智能体 Buzz 的工作流,利用 Slack 构建了一个极简的“人类反馈-Agent反思闭环”。
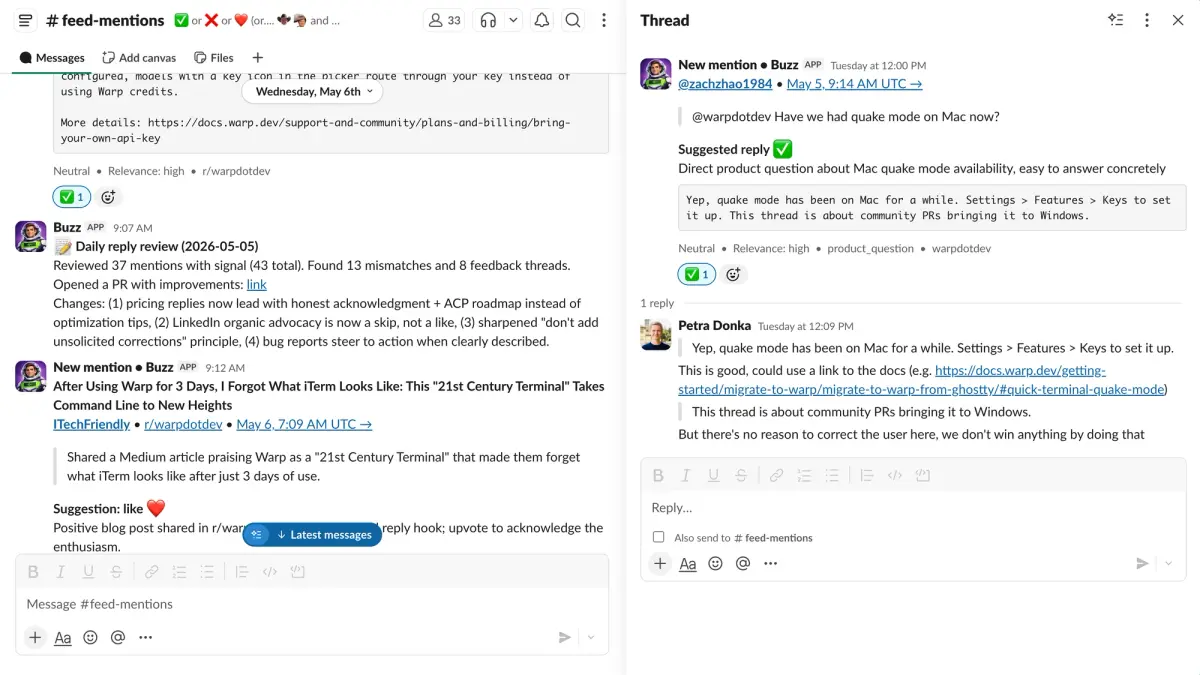
- Right: feedback to Buzz in a Slack thread. Left: the daily PR where Buzz links the resulting skill updates.
本篇将以一个开发者的角度去思考如何构建系统化反馈与深度反思机制。简单来说,就是我们应该如何收集数据(反馈)和如何利用数据进化(反思)。
Feedback
显式反馈
收集反馈最简单的一种方式就是像 Gemini 那样提供用户对上一次的回复进行点赞/踩、采纳/拒绝的直接交互设计,这些数据来源也被称为显式反馈(Explicit Feedback)。显式反馈能够提供明确的意图表达,是高置信度的标签数据。
隐式反馈
很多时候用户不会主动去点击反馈按钮,而是在对话中表达出自己的纠正指令(Corrections)和负面情绪(Dissatisfaction),比如说,“不对,刚才那个参数传错了,应该是 X”,这类回复,我们称作隐式反馈(Implicit Feedback),需要 Agent 主动去收集。
如果将“判断用户上一句话是否包含纠正意图或负面情绪”这一动作串行在 Agent 的主业务流程中,每次生成回复前都去同步执行,那会带来明显的弊端。
首先是性能损耗,这必然导致每次对话的响应延迟增加;其次是系统职责耦合,Agent 主流程的核心使命是专心解答和处理用户的当前诉求,底层的反馈收集与隐式意图识别不应该侵入并拖慢主逻辑。
基于以上的利弊权衡,我在这里的想法是:采用“旁路并发”的架构来实现隐式反馈的收集。
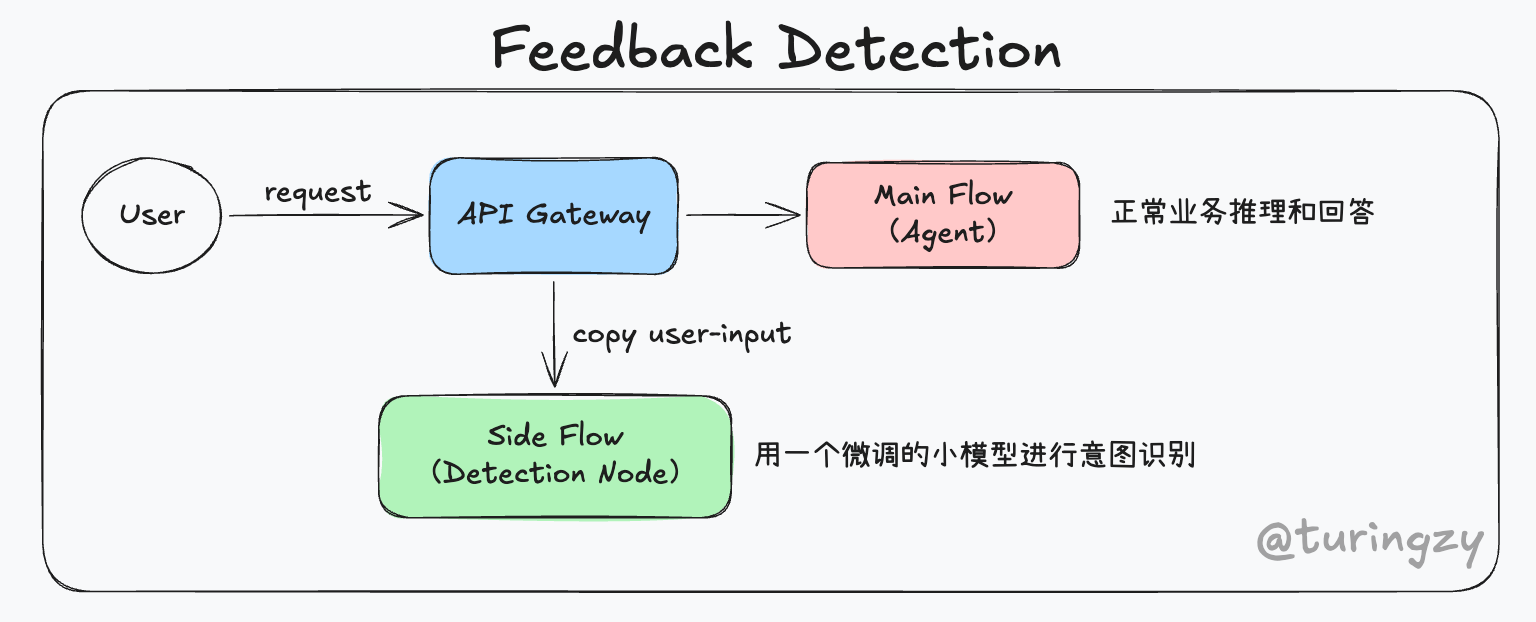
当用户的输入到达 API 网关时,通过消息分发或流量路由机制,将请求并行流转到两条独立的处理链路:
- 主业务链路 (Main Flow):承载核心对话任务。用户的请求直接进入主 Agent,进行正常的业务推理并向用户返回结果。
- 意图识别旁路 (Side Flow):在不打扰主流程的前提下收集隐式反馈,将用户的请求数据路由到一个专职“意图识别”的后台分析节点。
该旁路节点用一个专门微调过的轻量级小模型,主要行为是利用滑动窗口加载最近 N 轮的对话记录,在后台静默分析用户输入中是否包含纠正指令或负面情绪。
补充:Claude Code 中也有类似的检测,通过简单的负面词正则匹配在用户输入时轻量级地检测负面情绪或抱怨词汇,将其作为埋点信号用于评估用户体验和触发后续的反馈调查。
减少低价值反馈
小模型跑得快、省钱,但在处理极其微妙的用户交互时,往往会沦为“人工智障”,主要存在两大精度问题:
- 阴阳怪气的语境坍塌:用户发了一句“哇,你可真是个重置服务器的小天才呢”,小模型很容易只抓取到“天才”这个特征词,直接判定为
Positive Feedback,导致系统错过一次致命的 P0 级 Bug。 - 多意图混杂的特征丢失:用户抱怨“你找的文档全过时了,而且查个日志卡了半分钟”。小模型可能只能分类出延迟高,却把更核心的知识陈旧给遗漏,导致后续的修复建议文不对题。
基于以上原因,我们在“反馈收集”和“触发反思”之间,应建立一道基于置信度的拦水坝。
我们应该要求小模型在输出分类意图的同时,必须附带一个置信度分数(Confidence Score,如 0 到 1):
- 高置信区(> 0.75):信号极度明确,直接放行,给到待处理队列。
- 低置信区(< 0.40):大概率是无意义的口水话或小模型的幻觉,直接丢弃。
- 模糊地带(0.40 - 0.75):将这类反馈放入人工审核池。
除了模糊地带,对于那些高置信区的数据,也可以每天随机抽取 5% 混入人工审核池。
这不仅是为了防止小模型过于自信而犯错,更重要的是,对于人工纠正的这些错误反馈,会直接沉淀为高质量的微调数据集。研发团队可以利用这批 Golden Data 去微调小模型,不断拔高它在特定业务场景下的分类精度。
想要详细了解,可以看 RLHF 基于人类反馈的强化学习 这篇论文。
数据标准化
数据来源目前是上面这两种,后续可能会有其他方式,但不管如何,我们都需要对这些信息做标准化处理 Feedback Schema。
一条给 Agent 反思额反馈数据应具备以下属性:
0{
1 // 1. 基础系统元数据
2 "feedback_id": "fb_1234abcd",
3 "timestamp": "2026-05-26T10:00:00Z",
4 "session_id": "sess_987654", // 关联整轮会话追踪
5 "message_id": "msg_000001", // 关联出错的具体那条消息
6 "agent_version": "v2.1.0", // 系统版本
7 "model_name": "claude-3-sonnet", // 模型
8 "prompt_template_id": "prompt_v1", // 当时使用的系统提示词
9
10 // 2. 分类与来源
11 // 决定反思的处理优先级和策略
12 "feedback_type": "implicit", // 枚举值: "explicit" | "implicit"
13 "source": "SilentTools_Detector", // 数据源: 如 "UI_Button" 或旁路小模型名称
14
15 // 3. 负载
16 // 存放具体的反馈信号,显隐式结构互斥或包容
17 "payload": {
18 "action": null, // [显式专属] 如 "thumbs_down" (当前为隐式,故为null)
19 "detected_intent": "Correction", // [隐式专属] 旁路模型识别出的意图:纠正
20 "emotion_score": 0.8, // [隐式专属] 负面情绪置信度
21 "user_text": "不对,是重启服务器 B!", // 用户原始反馈文本
22 },
23
24 // 4. 状态
25 "status": "pending", // 状态: pending -> processing -> resolved -> ignored
26 "reflection_result": null // 反思处理结果
27}
数据标准化后,如果并发量不高,那么可以考虑直接落库(DB),这样架构简单落地也会更快;如果当前并发量高的话,可以用 MQ 进行解耦,架构虽然复杂但系统更稳定。
Reflection
当标准化反馈成功落库,并被标记为 pending(待处理)状态后,我们面临两个核心的设计考量:反思任务交由谁来执行?以及反思应在何时触发?
首先反思任务不应由负责线上交互的主 Agent 执行,我们应该遵循系统设计中的“职责分离“。主 Agent 的核心是快且准地解决用户的问题,它的所有 Prompt 和流程设计都围绕着交互体验和任务达成。因此,反思行为则应该交由一个完全独立的后台组件 —— Reflection Agent 来负责。
在面对突发的反馈洪峰时,如果每条反馈都“实时”调用大模型反思,会瞬间耗尽 API 的并发额度。相比之下,将反馈先存起来,让 Reflection Agent 定时去后台打包处理,或者干脆在系统低谷期统一排查,能巧妙地避开并发高峰。
知道了“谁来做”和“何时做”之后,就是“怎么做”的事了,在这里我推荐一个五阶段的流水线。
Reflection Pipeline
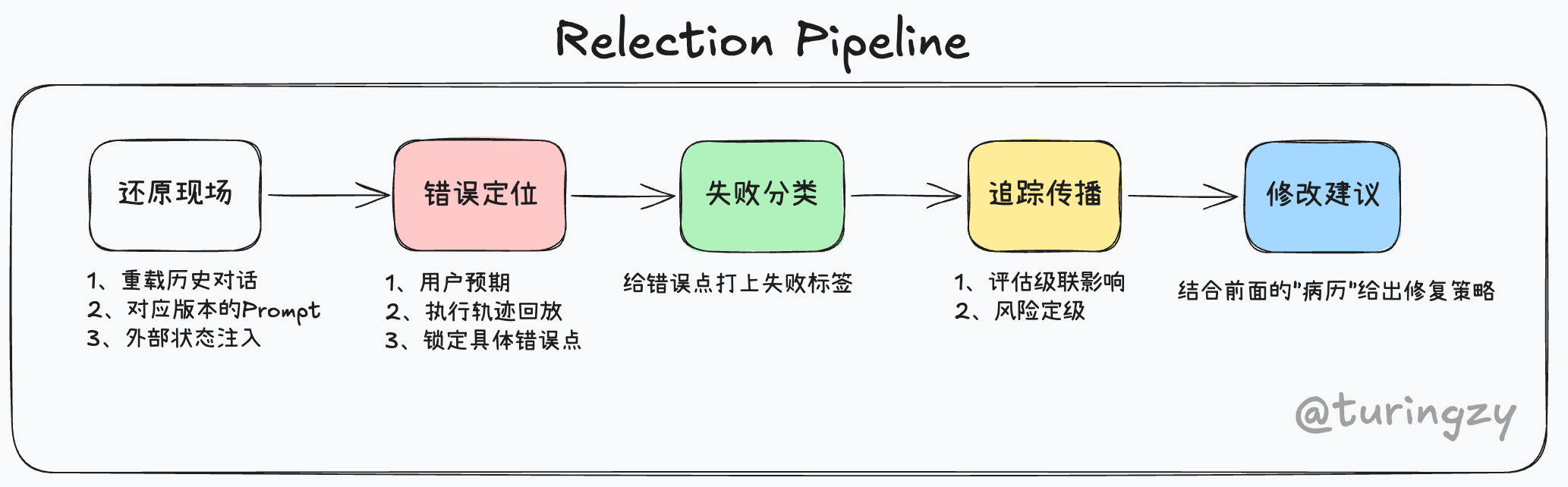
还原现场
1、重载对话历史
通过反馈数据中的 session_id 和 message_id,在业务数据库中拉取报错节点前 N 轮的 Message History。排错必须结合前置语境,但为了防止大模型上下文窗口溢出,须做截断处理(例如只保留最近 3 到 5 轮),剔除掉无关的久远历史。
2、提取具体版本号的 prompt
根据记录的 prompt_template_id 和版本号,去配置中心拉取案发时刻精确的 System Prompt。线上业务发版频繁,如果用当前最新的 Prompt 去反思历史错误,对照的基准线就彻底乱了。
3、外部状态注入
通过 message_id 关联 Trace 追踪库,提取出主 Agent 当时检索的 RAG 文档碎片、调用的 Tool_Schema 及其返回的 Tool_Result。业务库里只有一问一答的明文,如果不把大模型当时在后台“看到”的这些暗文状态拿出来,根本分不清是 API 给的数据有错,还是模型自己幻觉胡编。
错误定位
1、**预期与实际轨迹对齐
将反馈数据中用户的纠正指令(例如“不对,是重启服务器 B”),转化为大模型能够理解的“预期正确动作”,并将其与主 Agent 案发时的多步执行轨迹(包含 Thought、Action、Observation)并排对比。排错必须有标尺,有了清晰的“正确答案”和原系统的“错误步骤”,才能建立起比对的基准。
2、执行轨迹回放
让 Reflection Agent 沿着当时主 Agent 的执行链路,一步步往下审视。排查到底是在哪一环开始脱轨的,是第一步的意图路由走错分支了?是 RAG 查出来的文档有误导?还是工具选对了,但拼装的入参幻觉了?Agent 的执行往往是多步黑盒,如果不按节点逐个排查,大模型很容易给出一个笼统的“回答不准确”的废话,毫无价值。
3、锁定具体的错误断点
我们希望 Reflection Agent 输出一个精确的偏离节点位置。比如说,指出 Tool_Call: restart_server 节点的 server_id 参数提取错误。
0{
1 // 错误定位
2 "error_localization": {
3 "error_node_id": "node_4_tool_input",
4 "node_type": "Tool_Call",
5 "target_module": "restart_server_api",
6 "deviation_summary": "在提取参数时,将 RAG 召回的备用机(Server A)错误当成了用户的目标故障机(Server B)"
7 },
8}
失败分类
失败分类的本质是将非结构化的自然语言报错,转为可量化、可统计的结构化枚举值。在这一步的核心产物就是给引发失败的原因打上一个或多个失败标签。
- 知识不足:RAG 召回失败或底座模型缺乏相关领域知识。
- 幻觉:模型无中生有捏造了数据或 API 参数。
- 工具缺陷:底层调用的 API 报错、超时或 Schema 定义含糊。
- 逻辑谬误:模型未能遵循多步推理的因果关系。
- 意图误解:在最外层的 Router 阶段走错了业务分支。
- 格式错误:输出的 JSON 或数据结构不符合下游要求。
- 安全拦截:触碰了 Guardrail 或敏感词词库导致的强制阻断。
0{
1 // 失败分类
2 "failure_classification": {
3 "error_tags": ["逻辑谬误", "工具缺陷"]
4 },
5}
追踪传播
在这一步 Reflection Agent 将以错误断点为起点,沿着 Trace 日志向下游深挖脏数据引发的级联影响。
它的核心任务是划定“爆炸半径”,鉴别该错误是仅停留在文本回复的低危操作,还是已经作为合法入参逃逸并触发了修改数据库、下发指令等高危行为。基于这种污染边界的测算,Reflection Agent 会为该链路打上标准的风险定级标签,如 P0 致命或 P2 一般。
0{
1 // 追踪传播
2 "impact_tracking": {
3 "severity_level": "P0",
4 "blast_radius": "Write_Pollution",
5 "external_impact_flag": true,
6 "polluted_downstream_nodes": [
7 "node_5_api_execution", // 实际执行了错误的重启命令
8 "node_6_final_response" // 给用户返回了错误的确认话术
9 ]
10 },
11}
修复建议
在最后一步“修复建议”中,Reflection Agent 会基于前四步得到的病历(错误位置、失败分类、严重定级),生成一个可执行的修复策略。不会给出“请提高回答准确率”这种正确的废话,而是精确到具体的模块和配置,比如说:
如果是 Prompt 存在歧义,它会直接输出增删改的 Diff 建议;如果是知识遗漏,它会提示补充特定的 RAG 文档;如果是 API 故障,它会建议重构底层的 Tool Schema。
0{
1 // 修复建议
2 "patch_recommendation": {
3 "patch_type": "Tool_Schema_Update",
4 "target_component": "tool_registry.restart_server", // 明确指出要改哪个配置文件或模块
5 "issue_summary": "原 Schema 描述过于宽泛,导致模型在入参缺省时,会错误提取 RAG 检索结果中的备用机 ID 充数。",
6 "actionable_advice": "修改该工具的参数定义(Description)。要求强制补充一条规则:'必须验证 target 参数是否来自用户最新一轮的显式输入。若用户未提供,必须中止调用并反问用户,严禁使用历史上下文中的服务器名称脑补。'"
7 }
8}
离不开“评估”
在 Reflection Agent 给出反馈的修复建议后,我们还不能直接让 Reflection Agent 进行修复。
首先无论模型的诊断多么精准,直接应用其修复建议,都会面临极大的不确定性。因此,这套闭环的最后一步,我们还需要先做回归测试。
避免回归风险
修复问题 A 时,在 System Prompt 里塞进了一句校验规则;但这句新增的规则,极有可能会无意中破坏原本运行良好的问题 B 的处理逻辑。这就是 Agent 发中最让人头疼的回归风险。
因此,Reflection Agent 产出的修复建议绝对不能直接生效于线上主系统。必须先被部署到体验服,进行回归测试,让系统需要用客观的量化数据来证明:这个补丁不仅治好了眼前的 Bug,并且没有产生任何副作用。
沉淀测试集,把“线上踩坑”变成“离线资产
在进行评估测试的初始阶段,我们会用 10~15 个内部人员创建的测试集进行回归测试,但是测试集不可能只靠内部人员自己编写。
这套自我优化系统最具“长期复利”的设计就是,我们会让那份包含了“案发现场快照”和“用户预期”的诊断报告作为一个高价值的 Eval Case,添加到测试集中。
0{
1 "question": "xxxx",
2 "expected_answer": ""
3}
这意味着,系统在线上每犯一次错、被纠正一次,我们的回归测试集里就会多出一个来自真实场景的高价值 Eval Case。
总结
在过去的大模型应用开发中,我们往往陷入一种被动的泥潭:用户在前端报出 Bad Case,后端开发去庞大的日志里捞 Trace,人工推测原因,然后修改 Prompt 重新发版。
但通过这套 Reflection Agent 的反馈收集、 五步流水线反思与离线评估机制,让我们真正在架构层面上将散乱的线上报错,转化为驱动系统进化的结构化燃料。这就好比为原本黑盒的 Agent 装上了高精度的诊断系统,它不再是一个只会犯错的盲盒,而是一个能够自我归因、自我开药、甚至自我验证的智能体。
当前,我们依然需要人工去 Review 那份 reflection_result 并点击 Merge。没有达到完全的“自动化”。但我们可以想象一下这样的工作流:
在夜间业务低谷期,Reflection Agent 自动扫描挂起的负面反馈,拉起执行沙盒完成归因定级,生成 Patch Recommendation 并跑通上万条 Eval 回归测试集。当第二天早上打开电脑时,系统不仅自动修复了昨晚的高危缺陷,甚至连详细的 PR(Pull Request)报告都已经写好,就等我们最终确认。
参考
- NousResearch. Github(hermes-agent). Hermes Agent
- Petra Donka. Warp. Agents Need Feedback Loops, Not Perfect Prompts. 2026
- liuup. Github(claude-code-analysis). Claude Code 负面词检测
- Long Ouyang et al. arxiv. RLHF 基于人类反馈的强化学习. 2022