Agent 系列之上下文工程
引言
LLM 本质上是固化在磁盘上的超大参数文件。配备 HTTP 接口后,它可以被视为一个无状态的纯函数,纯粹依靠概率预测来输出结果。

以下面的基础对话为例:
0# 第一轮
1me:你好,我叫小明今年18岁,即将读大学!
2chatgpt: 很高兴认识你,小明!
3# 第二轮
4me:你还记得我叫什么名字吗?
5chatgpt:小明!
6# 第三轮
7me:那你知道我明年几岁呢?
8chatgpt:19岁
既然 LLM 完全无状态,那它是如何在第二轮和第三轮正确输出的呢?
这主要归功于 Harness Engineering 中的上下文(Context)机制。在进行后续对话时,系统会将前文的历史记录与当前提出的问题组合成完整的上下文,一并传给 LLM。
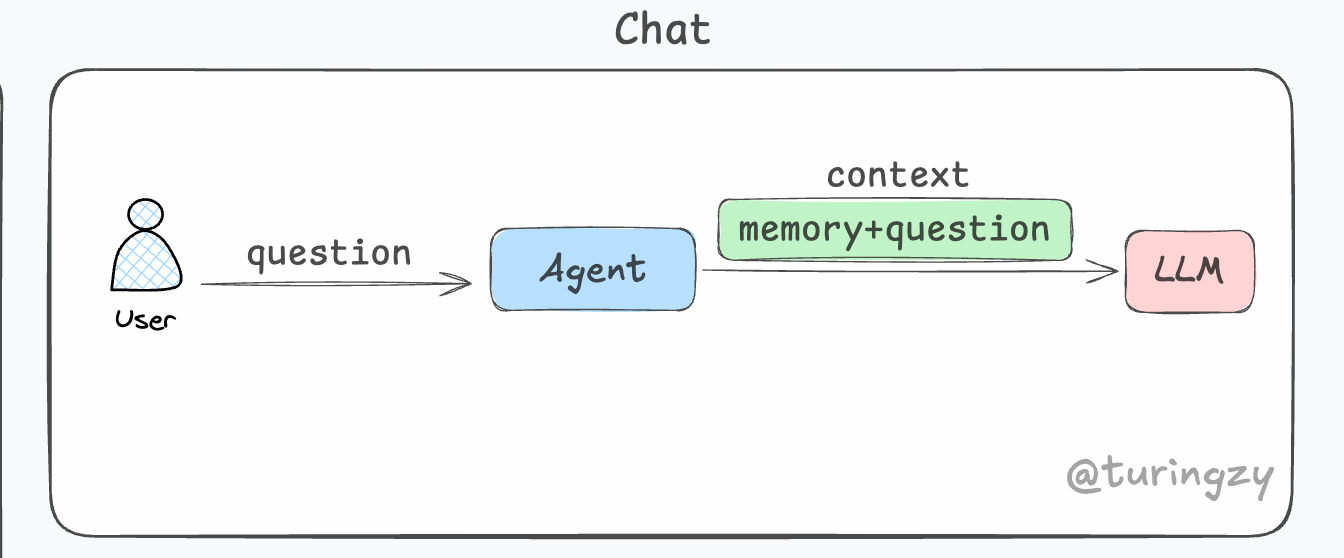
在工程实践中,上下文窗口(Context Window)就如同 Agent 的“工作内存(RAM)”。和人类的记忆机制类似,随着处理任务变多、时间变久,系统需要承载的信息量会剧增。尽管 LLM 本身不会“遗忘”,但它受限于物理上下文参数上限(如 8K、128K,乃至 Gemini 3 Pro 突破性的 2M Token 上限)。
Learn about language model tokenization,1 Token $\approx$ 4 个字符、1 个汉字。
当我们在大型项目上让 Agent 进行多步规划和代码编写(Vibe Coding)时,由于大量工具调用结果和执行日志的注入,仅几轮交互就可能导致 Token 爆满。因此,上下文工程(Context Engineering)的核心使命,就是像操作系统的内存管理一样,避免因为内存溢出(OOM)或信息过载而导致 Agent 崩溃。
上下文管理的四大维度挑战
如果将长会话中 Agent 面临的上下文问题进行拆解,主要集中在四个维度:
- 空间上的“放不下”(Capacity Limit),长任务运行中频繁出现上下文溢出或 API 报错,核心问题是上下文总量超载。
- 时间上的”记不住“ (Retention & Decay),随着历史拉长,模型开始出现注意力衰减与幻觉,核心问题是早期关键上下文丢失。
- 精度上的“找不准” (Signal-to-Noise),模型在大量杂乱的工具日志和冗余对话里迷失,核心问题是上下文信息密度过低。
- 逻辑上的“理不清” (Reasoning Confusion),模型在长序列的局部执行细节中,偏离了最初的任务目标,核心问题是上下文权重失衡。
渐进式上下文压缩(Progressive Context Compaction)
针对上下文管理,目前业界最成熟的做法是渐进式上下文压缩。渐进式压缩的根本目标并不是单纯地“让 Token 变少”,而是确保系统在上下文持续无限增长时,仍然能维持 Agent 工作的连续性与可用性。
在这一领域的工程实现中,Claude Code(后文简称 “CC”)无疑是标杆。
注:2026 年初 Claude Code 的源代码泄露,为我们了解其顶级的 Harness 架构提供了可能。参考 Claude Code 源代码分析。
CC 的上下文压缩并非单一算法,而是一个四层递进的复杂系统:
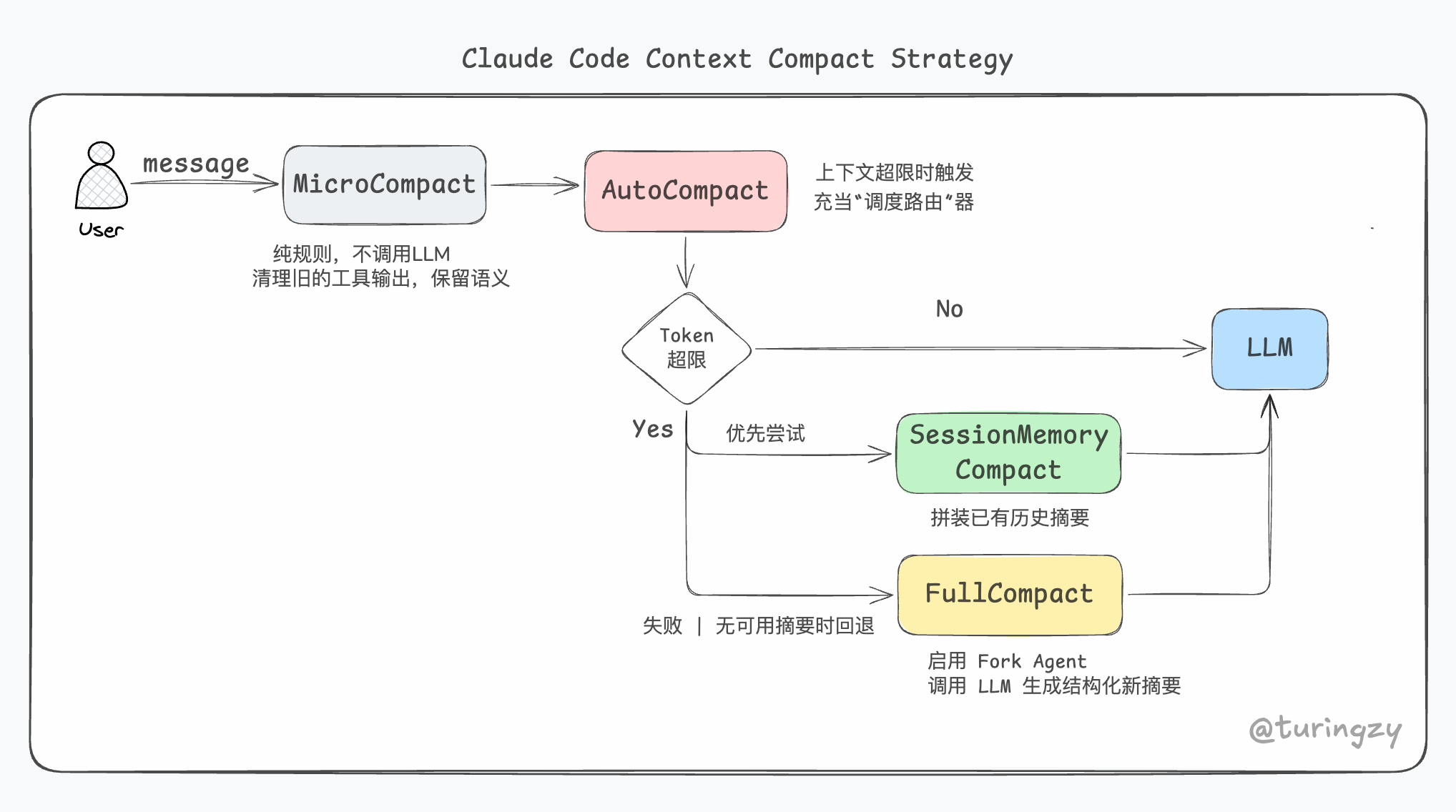
按照其架构设计,广义的上下文压缩可以划分为三个阶段:Pre Compact(预备与拦截)、Compact(压缩执行)、Post Compact(恢复与兜底)。这套系统本质上回答了四个核心工程问题:什么时候压?先压什么?哪些绝对不能丢?压完怎么无缝继续?
Pre Compact(预备与拦截)
在真正启动压缩前,系统需要完成状态监控、安全校验与数据清洗。
1. Token 估算机制
精确计算 Token 需要调用庞大的分词器(Tokenizer)。出于极速响应的性能考量,CC 采取了“启发式估算”策略:
0/**
1 * 估算逻辑:根据消息内容类型分发计算
2 * 规则:文本按字符转换,多媒体按固定权重,工具调用序列化计算
3 */
4function estimateMessageTokens(messages: Message[]): number {
5 const WEIGHTS = { IMAGE: 2000, DOCUMENT: 2000, BUFFER: 4/3 };
6
7 let totalTokens = messages.reduce((acc, msg) => {
8 if (!['user', 'assistant'].includes(msg.type)) return acc;
9
10 return acc + msg.message.content.reduce((sum, block) => {
11 switch (block.type) {
12 case 'text': return sum + (block.text.length / 4);
13 case 'thinking': return sum + (block.thinking.length / 4);
14 case 'image':
15 case 'document': return sum + WEIGHTS.IMAGE;
16 case 'tool_use': return sum + (JSON.stringify(block).length / 4);
17 default: return sum + (JSON.stringify(block).length / 4);
18 }
19 }, 0);
20 }, 0);
21
22 return Math.ceil(totalTokens * WEIGHTS.BUFFER); // 预留 33% 容错空间
23}
其核心思想是将复杂的上下文拆解为不同类型的数据块。对文本统一套用 4 字符 ≈ 1 Token 的粗略换算;对图片、文档等直接填充 2000 词的固定占位;最后全局乘以 4/3 的溢出补偿来对冲估算偏差。这是一种“宁可算多、不可漏算”的防御性编程。
2. 精准的触发阈值
系统设定了多道边界防线以合理触发不同级别的压缩:
- 时间微压缩边界:距离上次回复时间间隔超过服务端 API 缓存 TTL 时,直接清理本地失效的历史工具输出。
- 状态预警边界:当前 Token 占用 $>=$ 模型总上限 $-$ (摘要预留 + 20,000 缓冲) 时,触发前端警告。
- 自动压缩边界:当前总 Token 减去刚释放的 Token $>=$ 模型总上限 $-$ (摘要预留 + 13,000 缓冲) 时,正式拦截并触发压缩。
- 熔断与降级边界:压缩连续失败 3 次触发永久熔断;收到 API
prompt_too_long报错触发窗口物理切断。
3. 全局拦截校验器
作为启动压缩前的最后一道保险,防止系统陷入自我毁灭。CC 设定了五大约束:
- 防递归死锁:若请求来源本身就是负责压缩的子进程,强制拦截(防止套娃死锁)。
- 并发冲突拦截:若其他内部机制正在折叠历史记录,拦截以保护日志完整性。
- 后门配置拦截:检测到
DISABLE_COMPACT=true等调试变量时,宁可报错退出也绝不干预。 - 被动响应拦截:针对特定 A/B 测试,系统坚持“不见报错不撒鹰”的原则。
- 熔断拦截:连续压缩失败 3 次,直接放弃。
4. 消息规整化分组与附件剥离
历史消息不能按 Token 数量硬切,否则极易触发大模型的“孤立工具错误(Orphaned Tool Error)”。CC 以 API 返回的 message.id 为锚点,将模型调用与用户反馈打包为不可分割的区块。
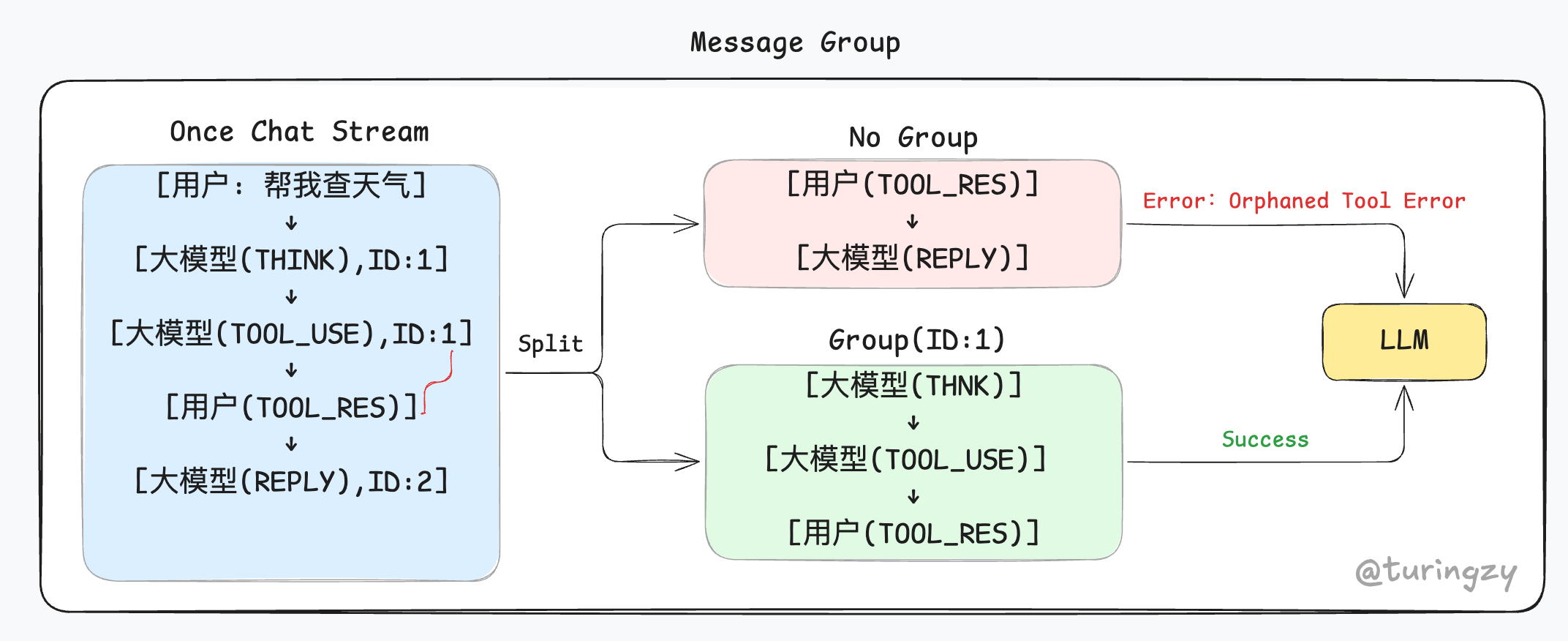
按 message.id 分组,能确保后续无论怎么删减或压缩历史记录,都是以“完整的 API 轮次”为最小插拔单位,保证工具调用的请求和结果永远成对存在。
同时,在将日志送往摘要模型前,会临时剥离所有图片与长文档,替换为 [image] 等占位符。这不仅防止了压缩进程自身 OOM,还消除了非文本噪音,让模型专注于理解对话逻辑。
Compact(压缩执行)
MicroCompact(微压缩)
首先我们需要知道,真正撑爆上下文窗口的往往不是对话,而是庞大的工具执行结果和系统日志。
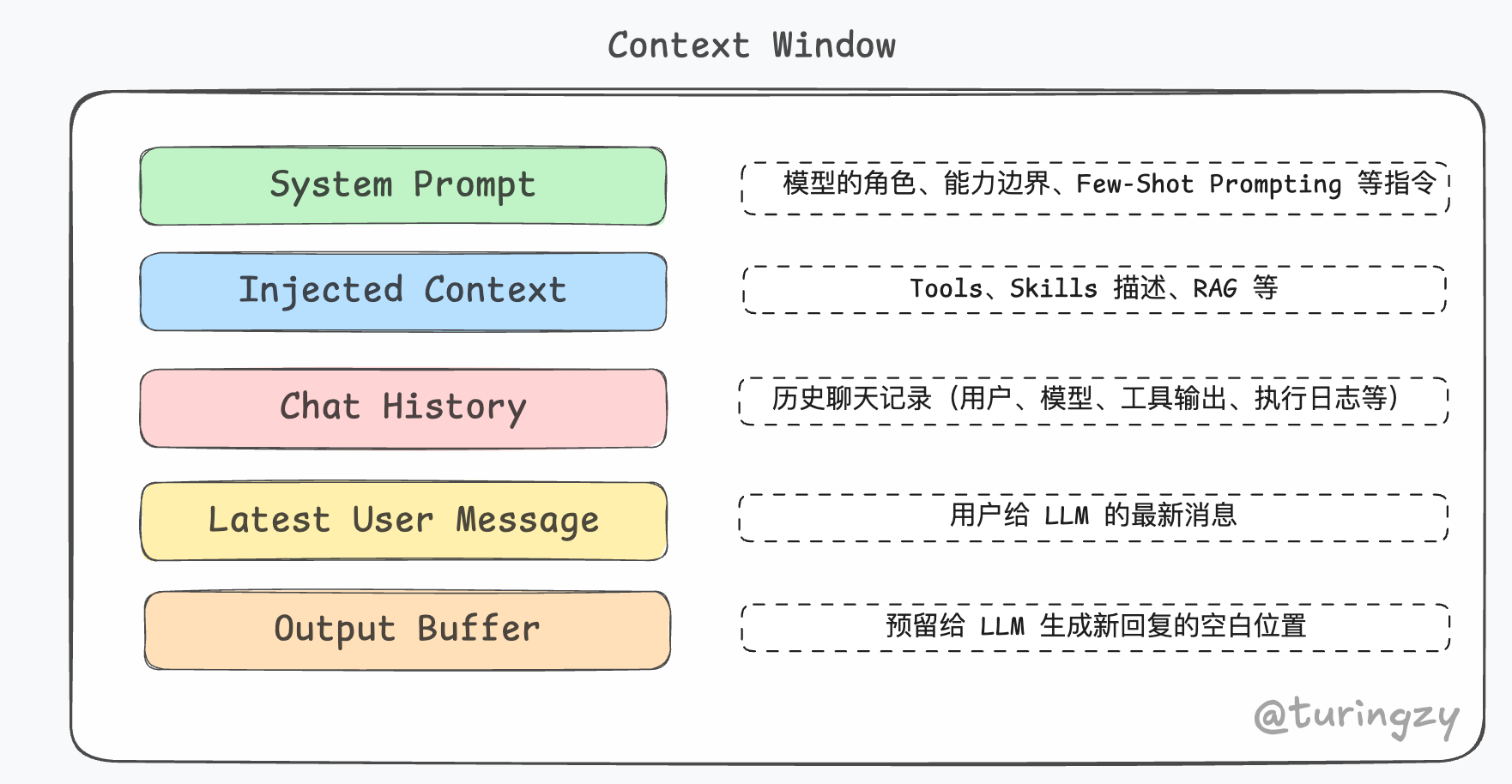
微压缩是 CC 的第一层轻量化压缩策略。它是一种基于预设规则(Rule-based)的静默清理手段,专门针对历史对话中那些体积巨大但逻辑价值随时间降低的 “工具输出结果”(如读取的长文件内容、大量的搜索结果或终端日志),将其替换为极简的占位符。
可压缩工具白名单:
0const COMPACTABLE_TOOLS = new Set([
1 'Read', // 文件读取
2 'Bash', // Shell 输出
3 'Grep', // 搜索结果
4 'Glob', // 文件列表
5 'WebSearch', // 网页搜索结果
6 'WebFetch', // 网页抓取结果
7 'Edit', // 文件编辑的 diff
8 'Write', // 文件写入确认
9])
微压缩仅针对特定工具的结果进行操作,不触碰用户消息和模型思考过程。并且采用两种执行策略:
- 本地替换:若判定服务端缓存已失效,直接将本地历史中的大块内容修改为
[Old tool result content cleared]。 - 缓存编辑:若服务端缓存仍有效,则通过 API 的
cache_edits参数发送删除指令,让服务器在推理时动态忽略这些数据,而无需改动本地历史记录。
提示词缓存优化:为了不破坏服务端的 Prompt Cache,CC 在开启缓存编辑时,会完整发送包含旧日志的上下文,但附加
cache_edits指令让服务器在推理前动态剔除废弃内容,完美平衡了“保缓存”与“省空间”。
执行时遵循 count/keep 机制,强制保留最近几轮的日志,确保短期记忆的高清度。此操作 0 模型调用成本,延迟极低。
AutoCompact(自动压缩)
自动压缩是一个完整的自动化决策流。它在后台通过具体的 “路由策略” 将 SessionMemoryCompact 和 FullCompact 组合成一套由快到慢、由廉到贵的阶梯式方案。
SessionMemoryCompact
CC 有一个后台进程会定期将用户对话摘要、当前 Plan、已读文件列表写入本地的一个记忆文件(Memory.md)。当触发自动压缩时,系统不调用 LLM,而是直接把这个现成的文件内容 “拼” 在最近的几条消息之前。
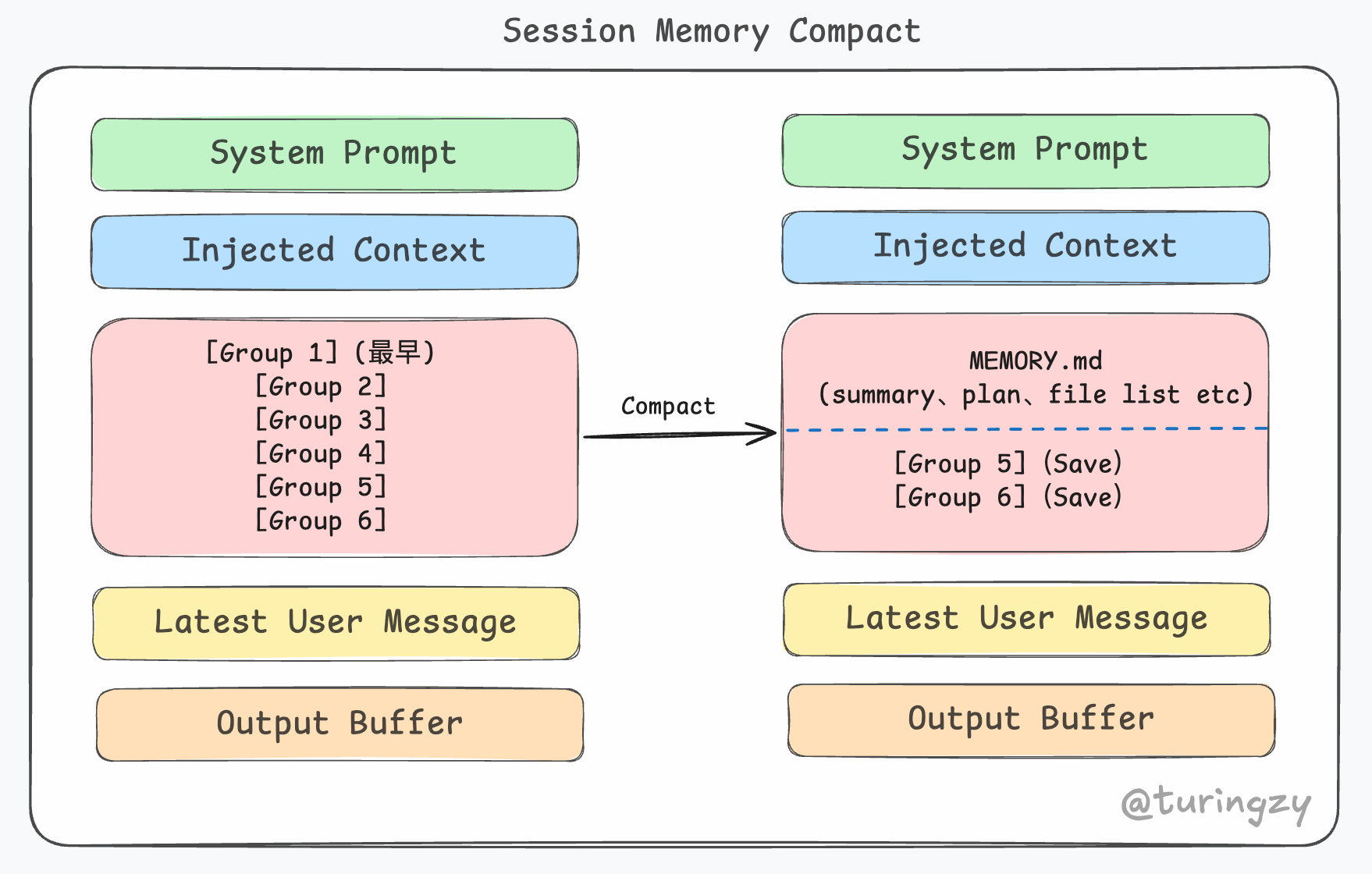
这种方式不消耗 Token 去生成摘要,也不需要开发者等待(延迟低),用户体感几乎是无缝的。但是如果后台进程还没来得及更新记忆文件,或者当前对话变化太快导致记忆文件“对不上”,这个路径就会失效。
FullCompact
如果本地记忆快照不可用,系统会 Fork Agent 进行深度压缩。该代理继承主会话的上下文状态,利用云端的提示词缓存读取已存在的历史记录,而无需重新传输。它使用专门的摘要指令,令模型输出一份包含逻辑反思与进度清单的结构化摘要。
0<analysis>
1[思考草稿——用于提高摘要质量的中间推理过程]
2[这部分最终会被删除,不会进入压缩后的上下文]
3</analysis>
4
5<summary>
61. Primary Request and Intent: [详细描述用户的所有请求和意图]
72. Key Technical Concepts:
8 - [概念1]
9 - [概念2]
103. Files and Code Sections:
11 - [文件名1]
12 - [为什么这个文件重要]
13 - [代码片段]
144. Errors and fixes:
15 - [错误描述]:
16 - [修复方式]
17 - [用户反馈]
185. Problem Solving: [问题解决过程]
196. All user messages: [逐条列出所有非工具结果的用户消息]
207. Pending Tasks: [待办事项]
218. Current Work: [精确描述当前工作内容,包含文件名和代码片段]
229. Optional Next Step: [下一步计划,包含最近对话的直接引用]
23</summary>
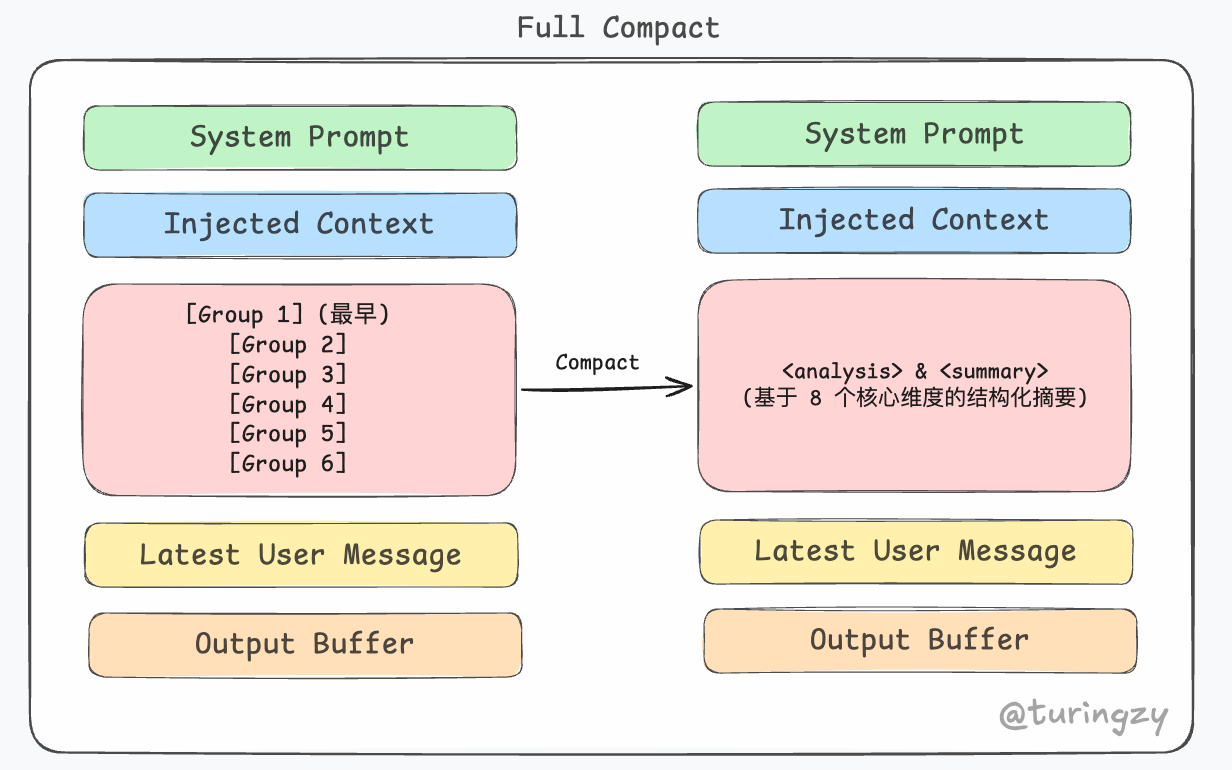
这一步虽然成本高、有延迟,但能将几万 Token 的流水账瞬间坍缩为高度浓缩的任务大纲。
Post Compact(状态恢复与异常兜底)
生产级架构的差距往往体现在“失败后的收场”。系统允许降级,但绝不允许瘫痪。
边界重建 (Boundary Rebuild)
边界重建的主要目的是要让系统在压缩后知道新旧上下文的边界在哪里。通过插入显式的语义路标(Boundary Message),在模型大脑中划清“历史摘要”与“当前现实”的物理界线,防止逻辑穿越。同时为后续的 Token 计算与消息裁剪提供一个准确的“起始线”。
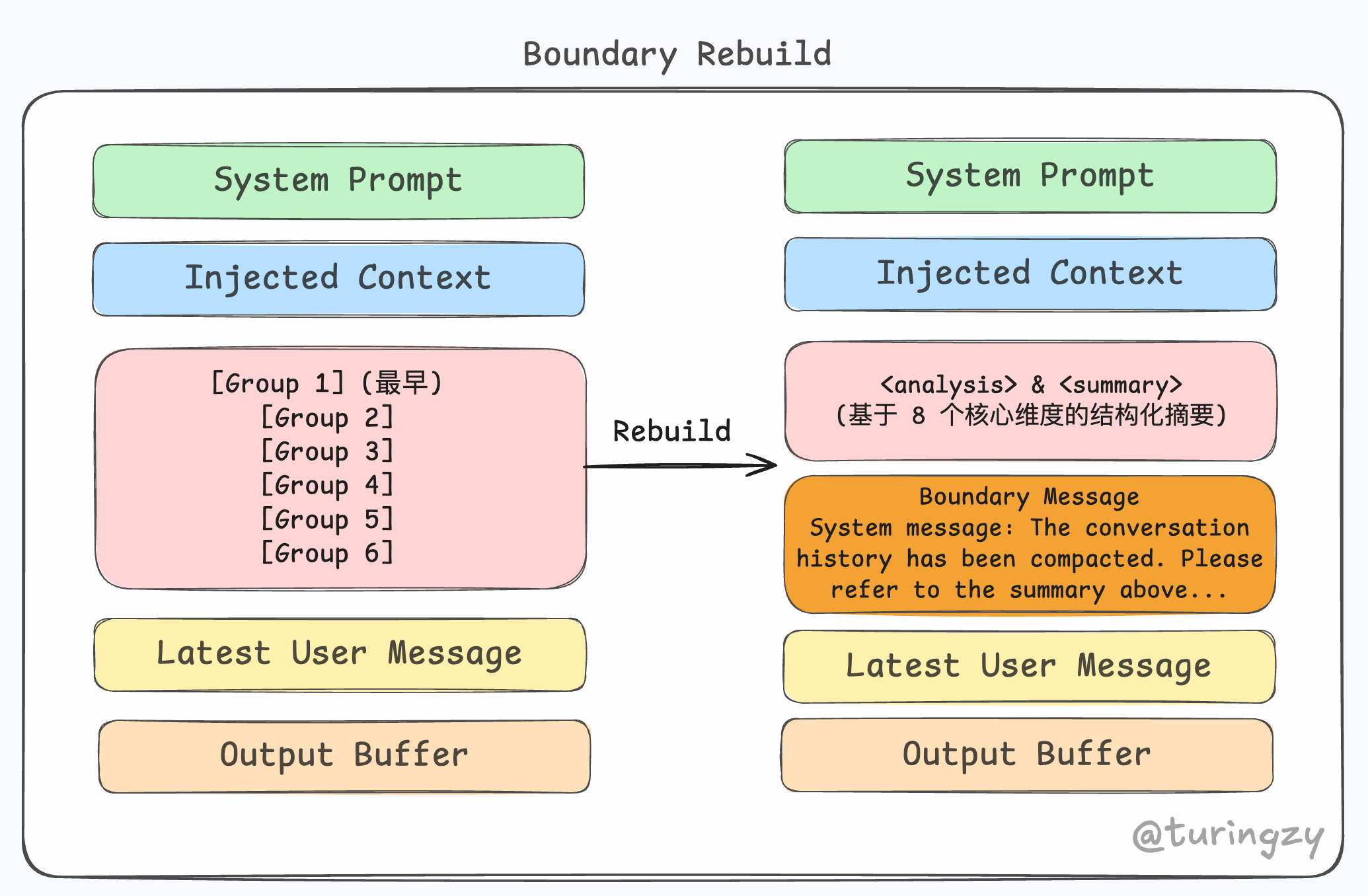
CC 主要通过下面三个函数来完成重建操作:
createCompactBoundaryMessage:生成特殊的边界引导消息对象,作为隔断历史摘要与当前任务的物理界线。findLastCompactBoundaryIndex(messages):在全局消息数组中反向检索,精准定位最新一次植入的边界消息的索引位置。getMessagesAfterCompactBoundary(messages):利用界线索引对消息数组进行物理切片。
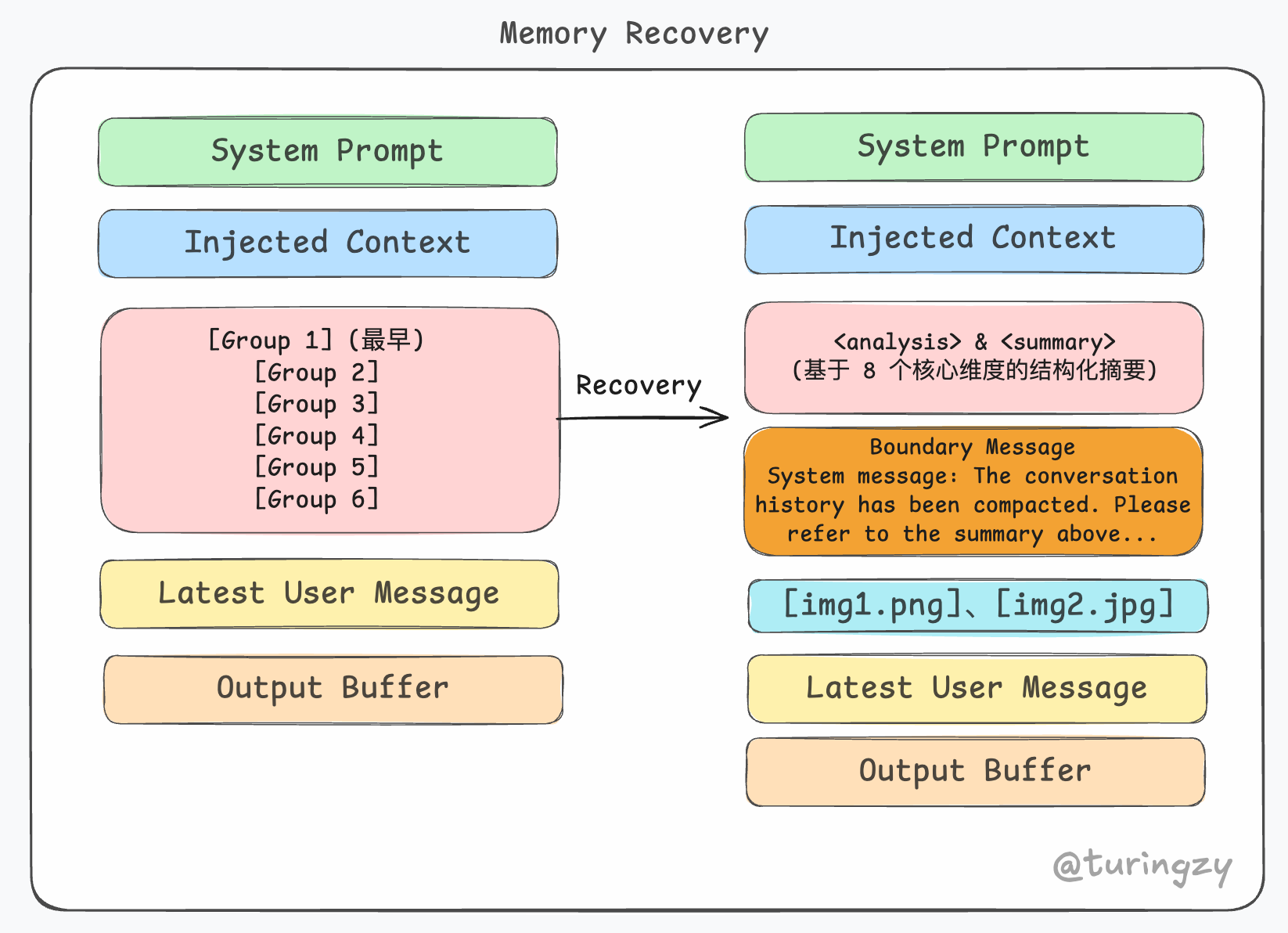
附件回填
在 Pre Compact 阶段,系统为了脱水,会把对话里巨大的附件(尤其是 Base64 编码的图片)全部“扣”出来,换成一个类似 [Image1] 的文本占位符。
附件回填就是一次记忆恢复手术,配合边界消息,把最近一两轮对当前任务至关重要的附件重新注入上下文,确保在经历大幅度压缩后,依然能无缝执行当前正在进行的视觉或文件处理任务。
熔断降级 (Circuit Breaker & PTL Fallback)
在自动压缩阶段,系统可能会遭遇服务端宕机、持续限流,或是上下文中混入了无法解析的“毒药”数据等极端异常。为了防止系统陷入“不断发请求 -> 不断报错”的死循环从而彻底卡死 Agent,引入熔断降级机制是保障系统高可用性的最后防线。
监控拦截与触发机制。该机制部署于触发全量压缩逻辑的外层调度器/拦截器中(如 autoCompact.ts 模块)。它在向大模型发送“写摘要”的 API 请求前进行状态拦截,并在执行流程的 catch 块中更新错误状态。
系统底层通过维护一个连续失败计数器来监控。当遇到网络抖动或限流等错误时,系统会自动进行重试,但每次捕获到异常,计数器便会 +1(期间只要有一次压缩成功,计数器立即归零)。一旦短时间内的连续失败累积达到设定阈值(通常为 3 次),断路器即刻弹开,正式触发熔断。
三步有损降级策略。触发熔断后,系统会放弃无意义的重试,转而执行一套标准的降级流程,以牺牲部分历史数据为代价来保全主程序的运行:
- 网络断流:彻底短路当前压缩任务,停止向 API 抛出无效的摘要生成请求,防止隐形的 Token 成本消耗。
- UI 释放与告警:立刻清除终端界面的
Compacting...阻塞状态,抛出非阻塞式警告,将控制权交还给用户,并建议其执行/clear指令重置上下文环境。 - 上下文截断(PTL Fallback):系统会采取最暴力的物理切除手段——直接裁掉最早期 10%-20% 的对话历史,以此腾出空间,确保 Agent 能够跳出死锁继续执行当前任务。
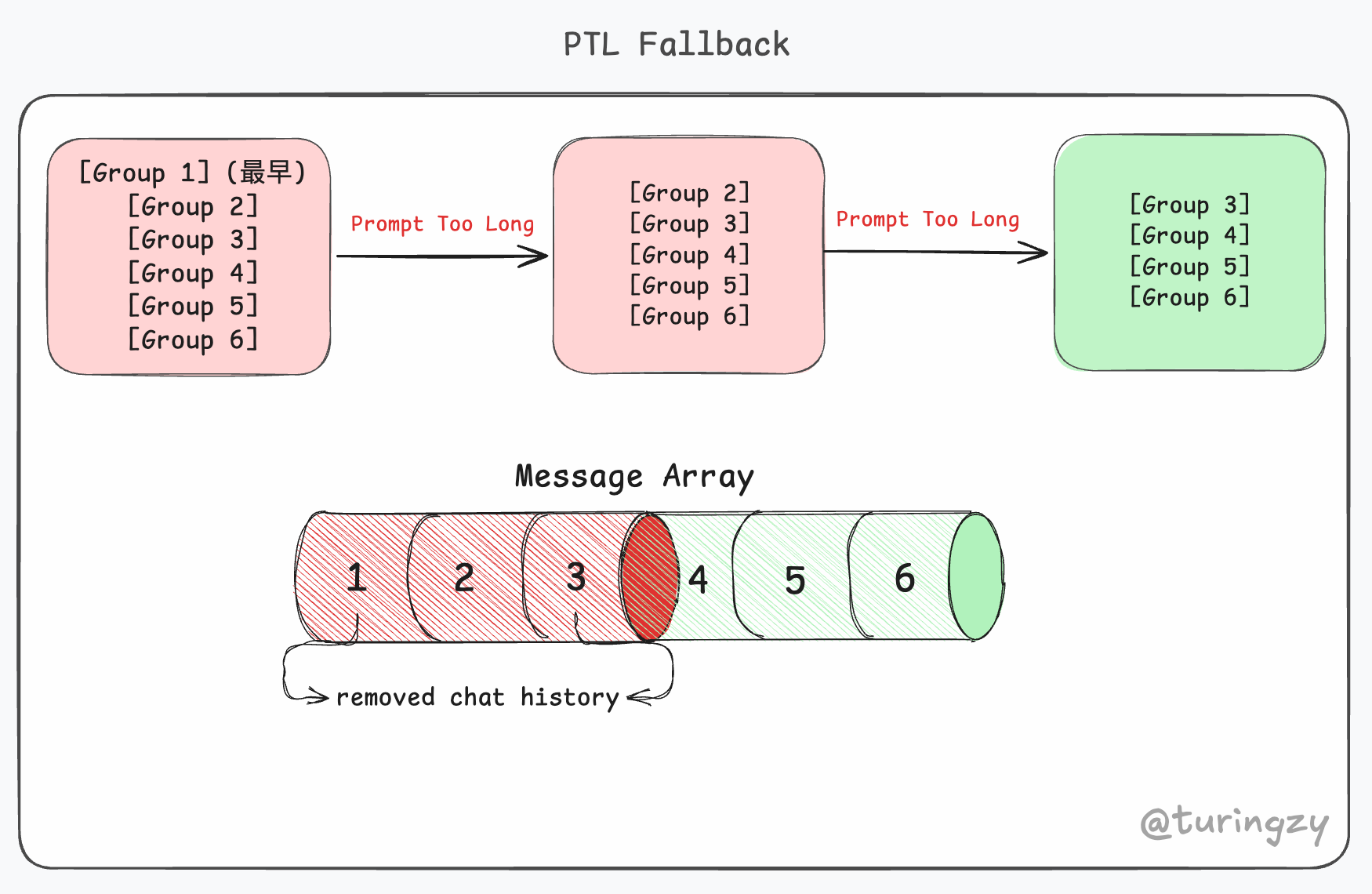
扩展
对于上下文压缩策略的选择,本质上是对「什么是重要的」这个问题的回答。
Manus 的上下文管理 与 Claude Code 展现了截然不同的工程哲学。
相比 CC 精密的“内存切片与摘要手术”,Manus 选择的是“文件系统外置与缓存优先”:
- 状态管理差异:CC 在 Context Window 中反复揉捏上下文;Manus 则将“文件系统”视为终极大脑。它主动将大文本剥离出 Prompt,只在上下文中保留文件路径,实现极端的 Token 瘦身。
- 压缩理念差异:CC 笃信“生成式摘要”及绝境下的“物理切除”;Manus 则认为不可逆的压缩会导致致命信息丢失。它采用“可恢复压缩”,坚决不盲目丢弃底层数据。
- 注意力机制差异:CC 利用显式的 Boundary Message 维持目标感;Manus 则引入了类似人类行为学的复述机制(Rehearsal)——让 Agent 强迫自己不断重写
todo.md文件,将全局计划拉扯到视野末端,防止迷失。
参考
- OpenAI. OpenAI Platform. tokenizer
- Wikipedia. 分词器(Tokenizer)
- liuup. GitHub(claude-code-analysis). Claude Code 源代码分析
- Manus. Manus Blog. Manus 的上下文管理