Agent 系列之行为范式
在当前的大模型应用开发中,Agent(智能体)无疑是最核心的焦点。但你可能会发现,即便底层使用的是同款大模型,不同的 Agent 产品(如 Claude Code、Cursor 等)在实际表现和稳定性上却有着天壤之别。
这背后的核心差异,正是来自于系统架构与认知逻辑的设计。OpenAI 将 Harness Engineering(驾驭工程) 定义为一门学科:“如何设计脚手架,使 Codex 和类似的代理能够在以代理为先的世界中可靠地运行。”
什么是 Harness Engineering?
推荐先看 Harness Engineering 是什么?和提示词工程和上下文工程有什么关系?,Up 总结得非常棒。
An Agent Product = Model + Harness 非常形象的公式!
Harness Engineering 就是让模型能够稳定输出的一种工程化结构,通过编排、记忆、执行、反馈等马甲来让大模型的能力更加稳定和强大。
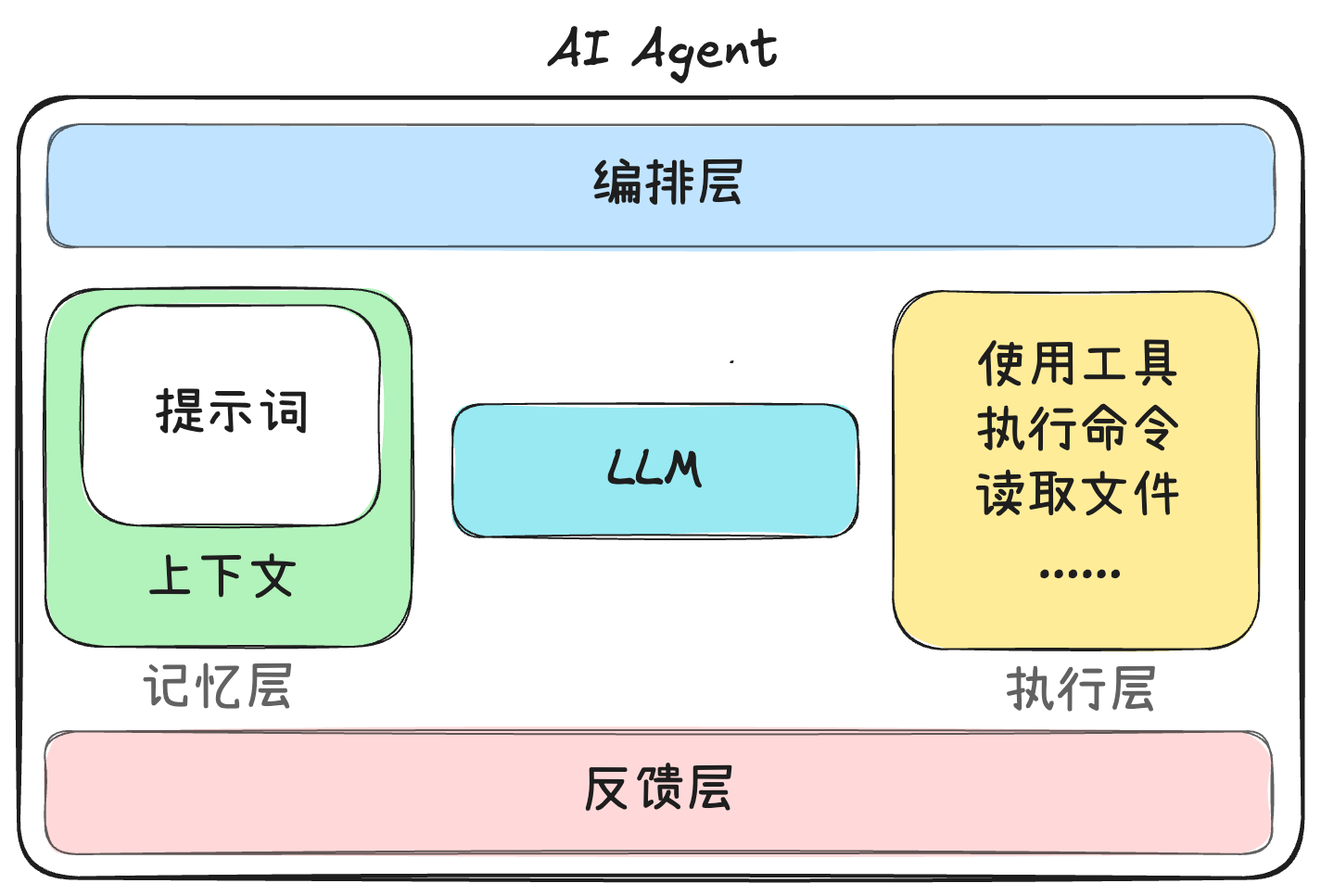
如果使用的模型能力越强,这些“马甲”相对而言就可以做得更轻薄(Less Structure, More Intelligence)。这些”马甲“可以看作是模型的一层补丁,用来补充当前模型欠缺的能力。
LLM 行为范式
如果说 Harness Engineering 搭建了 Agent 稳定运行的“物理底盘”,那么行为范式则是在此之上,为大模型装载的“认知引擎”。
简而言之,Harness 决定系统“会不会崩”,行为范式决定模型“怎么想”。在深入 Harness Engineering 前,先了解 LLM 最核心的行为准则,非常重要!
ReAct(推理与行动循环)
《ReAct: Synergizing Reasoning and Acting in Language Models》首次提出将大模型的“内部逻辑推理(Reasoning)”与“外部物理行动(Acting)”紧密交织在一起。通过强制模型在采取任何行动前显式地暴露思考过程,并在执行后被动接收环境的真实客观反馈,它彻底打破了大模型依赖预训练数据“开环盲猜”的幻觉死局,正式确立了让模型“走一步、看一步、动态纠偏”的核心行为底座。
ReAct 模式是大模型处理复杂任务时最经典的行为范式。
它彻底打破了模型接收问题后“一次性脑补输出”的开环死局,强制模型进入一个“动态试错与自我纠偏”的交互闭环:The ReAct Loop。
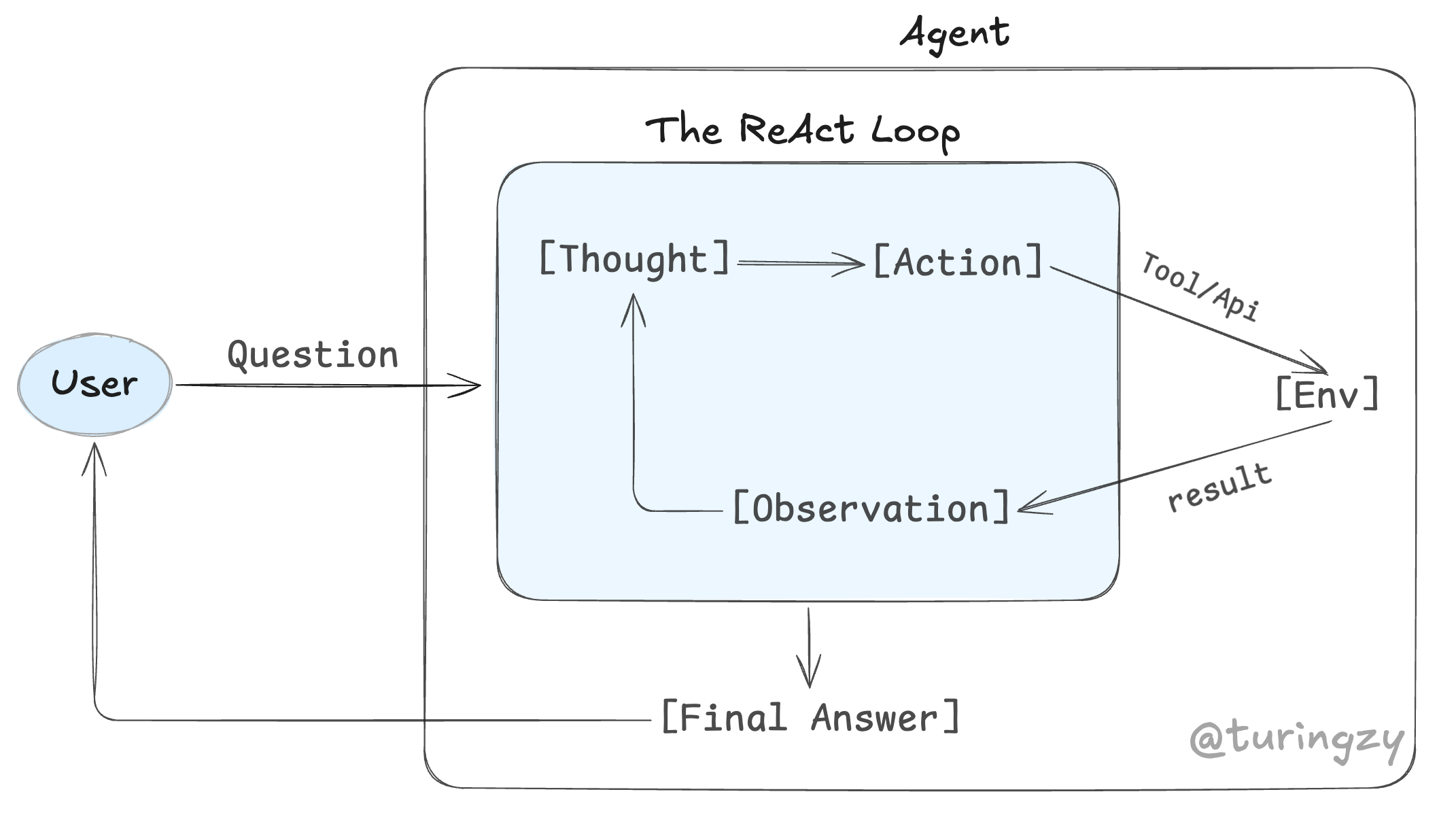
核心流转机制:
[Thought]推理:谋定而后动。模型在执行前,需要先输出明确的逻辑推导(如:“要查 500 报错,我得先看日志”),遏制盲目生成。[Action]行动: 基于思考,模型决定调用特定工具,并向外输出动作指令参数。[Env]物理执行与反馈:动作指令跨出认知循环,交由外部执行层真实运行。运行的客观结果(或报错堆栈)化为[Observation]重新注入循环。- 闭环修正:模型获取外部反馈,调整上下文,再次回到
[Thought]修正思路。反复自旋,直到得出确凿结论,跳出循环输出[Final Answer]。
通过这种“边思考、边动手、边根据反馈纠偏”的循环,ReAct 让大模型摆脱了纯粹的文本接龙幻觉,真正具备了在物理世界中落地执行多步任务的能力。
Plan-Execute-RePlan(计划动态重排)
《Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models》这篇论文首次系统性地提出,面对复杂任务时应避免使用传统思维链(CoT)进行盲目地一步步推导,而是强制模型先统揽全局,将大目标降维拆解为一个完整的子任务队列(Task List)后再行求解。
《Reflexion: Language Agents with Verbal Reinforcement Learning》确立了“动态纠偏”的理论核心。论文提出,当外部环境返回失败结果时,大模型仅凭将错误堆栈或异常结果转化为文字形式存入上下文,就能以此作为客观依据,对后续的执行策略进行自我反思与重新规划。
Plan-Execute-RePlan(动态重排)是大模型应对复杂、长逻辑链任务的核心行为范式。
模型首先将宏观目标拆解为具体的子任务队列(Plan),交由系统逐步执行(Execute);在执行过程中,系统会将外部环境的真实物理反馈(如执行结果、数据缺失或报错拦截)实时传回给模型,模型据此重新评估当前局势,并动态调整或彻底重写后续的任务路径(RePlan),直至最终达成目标。
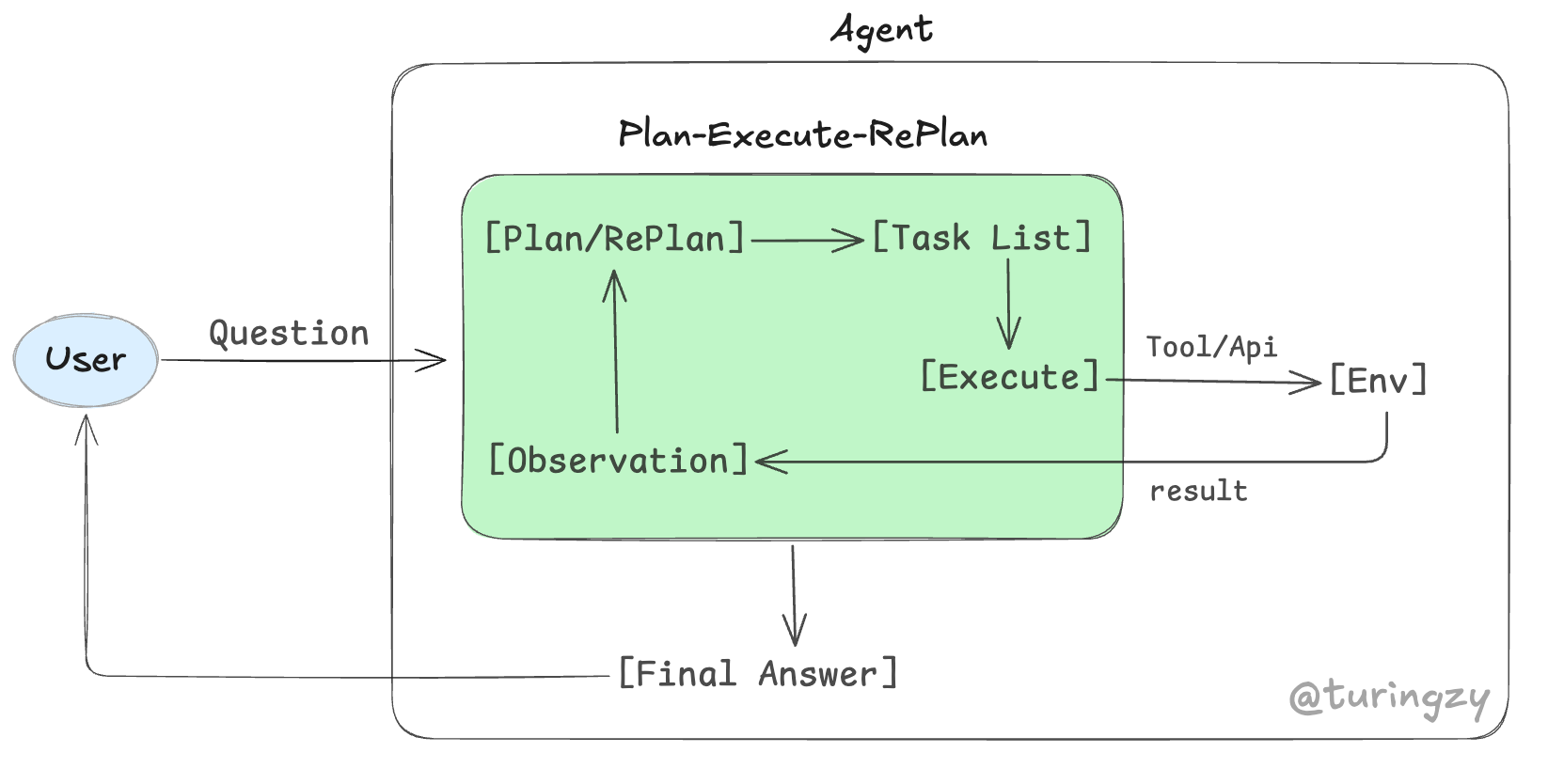
核心流转机制:
[Plan/RePlan]规划与重排:全局规划与动态纠偏。模型在接收目标后,需先将其降维拆解为宏观的任务队列(Task List);若后续收到执行异常反馈,则强制重新审视局势,推翻旧列表并动态重写剩余计划。[Execute]执行:从任务队列中提取原子任务,给外部环境(Env)进行真实的工具或 API 调用。[Observation]执行反馈:捕获外部环境返回的真实运行结果或底层报错堆栈,将其包装回传,作为模型决定是否触发“重计划”的客观依据。
Reflection(自我反思与纠错)
《Self-Refine: Iterative Refinement with Self-Feedback》该论文证明了即使不借助外部工具(Env),纯靠大模型自身的内部“左脚踩右脚”(自我反馈与自我修正),也能在代码编写、数学推理等任务上实现极其显著的质量跃升。
如果说 ReAct 是为了“跑通流程”,Plan 是为了“不迷路”,那么 Reflection 就是为了“保证输出质量”。
在面对代码生成、架构设计或高要求文案时,单次生成的质量往往不可靠。Reflection 范式将大模型的角色一分为二:它既是“生成者”,也是“评审员”。通过引入“自我批判”的内部回路,让模型在将最终结果交付给用户前,先进行内部的交叉验证和迭代优化。
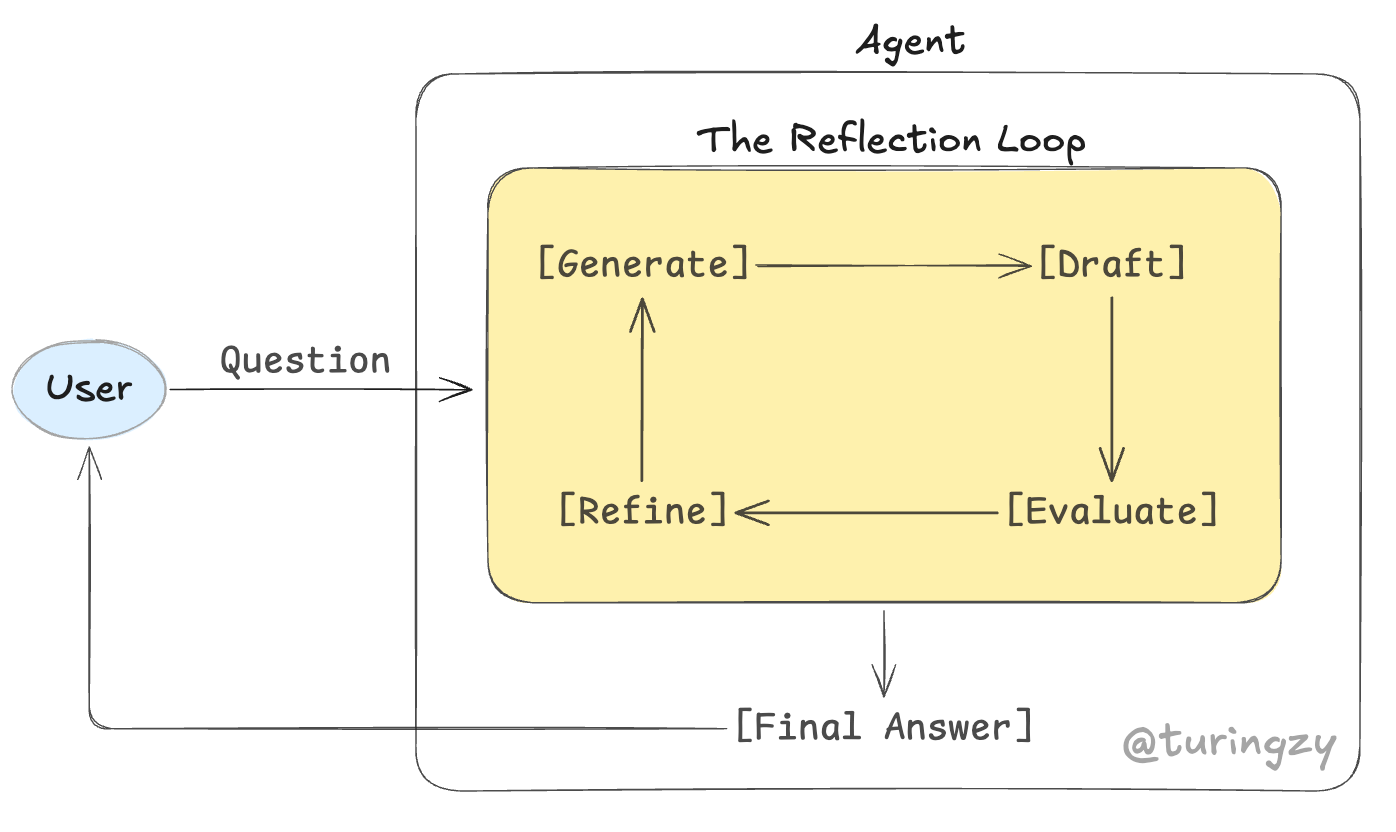
核心流转机制:
[Generate]初稿生成:模型根据初始任务目标,不带任何阻碍地生成第一版方案或代码(Draft)。[Evaluate]交叉评估:视角切换。模型切换身份,以严苛的“评审员”视角审视初稿,挑出逻辑漏洞、语法错误或不符合要求的地方,并输出具体的修改建议。[Refine]迭代优化:吸收反馈。模型重新回到生成者视角,根据评审建议,对初稿进行针对性的修改。通常设置最大迭代次数(3 次),直至评审员认为达标,再跳出循环输出最终结果。
Multi-Agent Conversation(多智能体协同)
《AutoGen: Enabling Next-Gen LLM Applications》系统性地定义了多个具备不同设定的 Agent 如何通过对话进行接力、纠错和状态转移,正式确立了多 Agent 协同在复杂软件工程中的统治地位。
当系统复杂度极高时,单体 Agent 会面临性能与能力瓶颈,单一的 System Prompt 无法兼顾所有业务(既要懂前端又要懂底层并发),且杂乱的全局执行日志会导致严重的上下文污染,极大增加内存压缩的负担。
Multi-Agent 应运而生。它不再强求一个“全能神”,而是将系统拆分为多个专职的 SubAgent。每个 SubAgent 只拥有极度精简的特定上下文和专属工具,通过“路由与状态交接”来协同完成任务。
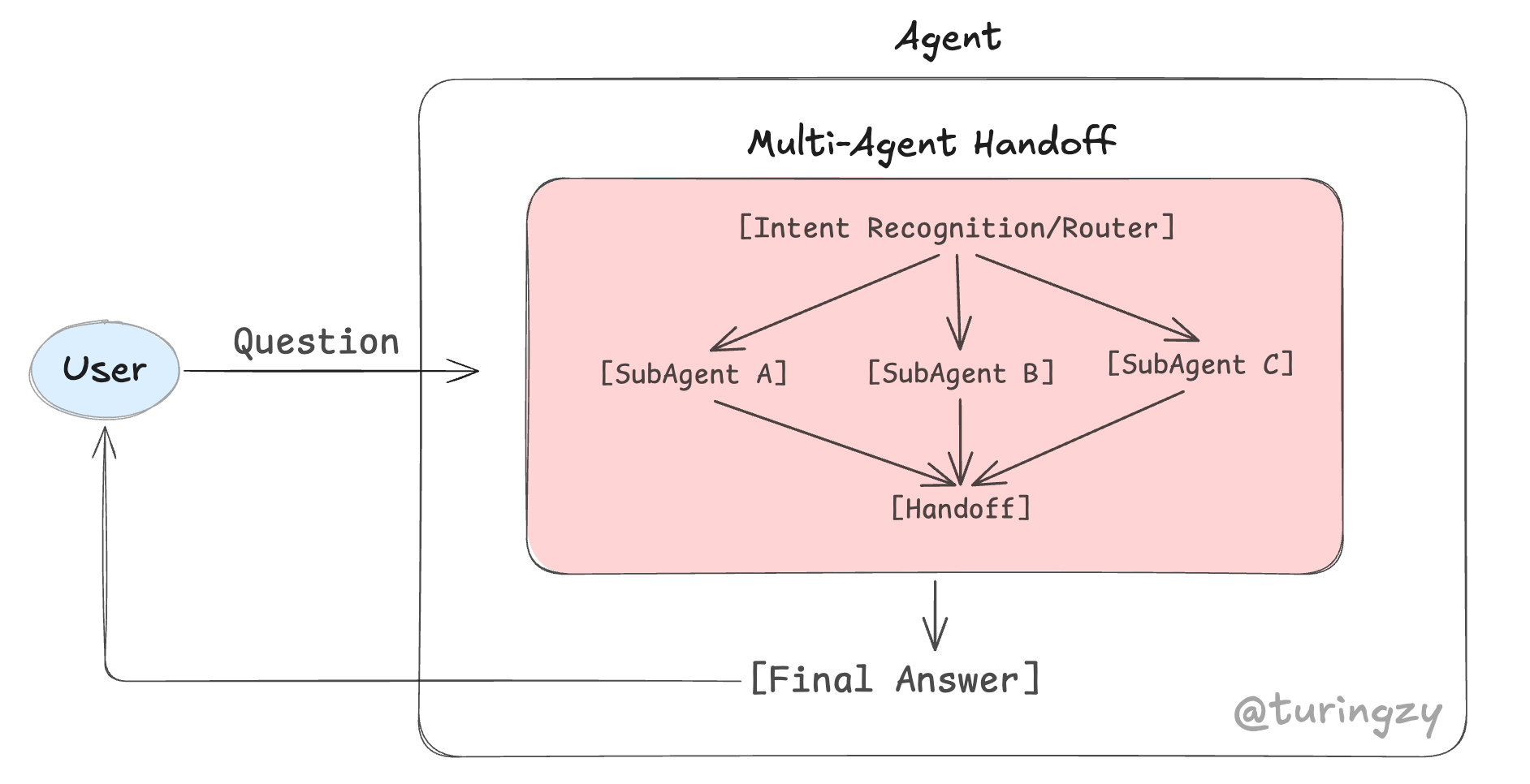
核心流转机制:
[Intent Recognition/Router]意图路由:主控 Agent 接收用户请求,识别当前任务所属的领域,并将其派发给对应的专职 SubAgent。[Agent Execution]专精执行:领域隔离。被唤醒的 SubAgent 带着纯净的、无冗余的 System Prompt 和专属工具库,在自己的沙箱内执行特定的单体逻辑(如启动一个小型的 ReAct 循环)。[Handoff]交接:状态传递。当前 SubAgent 完成份内工作,或发现需要其他领域的协助时,它会将自己的核心执行结果打包,移交给下一个 SubAgent,或者交回给主控 Agent 重新派发。
Multi-Agent 目前三种不同的实现形式:SubAgents、Agent Teams、Agent Swarm。
在多智能体架构的演进中,SubAgents 采用相互隔离的并发机制,子节点之间互不通信、独立执行,最终由主控 Agent 统一汇总计算结果,这种模式天然契合边界清晰、低耦合的独立任务。相比之下,Agent Teams 更侧重于网状协作,主控 Agent 通过共享任务清单进行全局调度,并允许子节点之间互相通信与状态流转,以应对逻辑依赖较强的复杂任务。而 Agent Swarm 则是对 SubAgents 并发能力的极致增强,它在维持子节点上下文物理隔离、确保其专注局部任务的基础上,引入了动态机制;当某个节点面临多重任务负载时,能够动态孵化新的 Agent 投入并行队列,通过算力的弹性裂变来应对高并发场景。
小结
ReAct 就像是“走一步看一步”。它讲究一边局部思考一边上手实操,外部环境给出的每一次真实反馈,都会直接决定我们大脑下一步的决策走向。
Plan-Execute-RePlan 则讲究“谋定而后动”。遇到大需求先不着急干活,而是把复杂任务拆解成全局的子任务队列,再挨个落地。如果在执行中出了问题,就停下来,结合现状重新规划剩下的路线。
Reflection 则是为了“兜底质量”。它要求我们在每次交卷前,先停下来自我审视一番,看看之前的解答有没有逻辑漏洞,或者是否存在更优雅的解法。
Multi-Agent Conversation 强调的是“术业有专攻”。它教会我们认清单体模型的能力边界,让专业的人干专业的事。就像造火箭,小组 A 只管助推器,小组 B 专门负责脱轨系统。大家在各自绝对擅长的领域发力,做好边界交接,让整体效率翻倍。
大模型行为范式的演进就像是我们人类面对不同情况的不同解法,没有最好的,只有最适合的!
参考
- 小白debug. 哔哩哔哩. Harness Engineering是什么?和提示词工程和上下文工程有什么关系?. 2026
- Ryan Lopopolo. OpenAI .Harness Engineering. 2026
- shareAI-lab. Github(learn-claude-code). An Agent Product = Model + Harness
- Yao et al. arxiv. ReAct: Synergizing Reasoning and Acting in Language Models. 2023
- Lei Wang et al. arxiv. Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. 2023
- Noah Shinn et al. arxiv. Reflexion: Language Agents with Verbal Reinforcement Learning. 2023
- Aman Madaan et al. arxiv. Self-Refine: Iterative Refinement with Self-Feedback. 2023
- Qingyun Wu et al. arxiv. AutoGen: Enabling Next-Gen LLM Applications. 2023
- 小白debug. 哔哩哔哩. Agent Teams/Swarm 究竟是什么?7 分钟看懂 100 个 Agent 团战的技术原理. 2026