Agent 系列之执行系统
引言
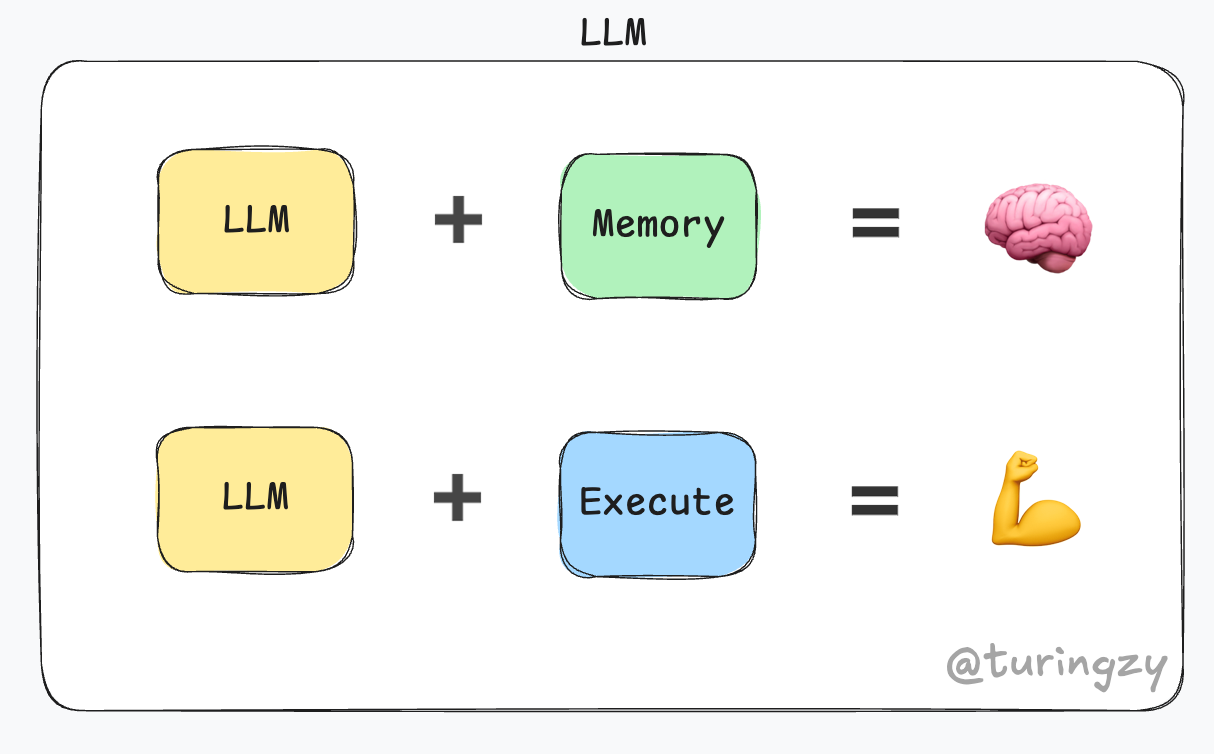
如果说“记忆系统”是 LLM 的大脑,那么“执行系统”就是 LLM 改造物理世界的机械臂。
在深入执行系统之前,我们需要先理清几个极易混淆的核心概念,归纳如下:
| 概念 | 所在层级 | 作用 | 构建方式 |
|---|---|---|---|
| Function Calling | LLM 层 | llm 使用工具的能力 | 模型原生能力,通过训练得到 |
| Tool | Agent 层 | Agent使用工具的能力 | Agent 框架对 Function Calling 能力的封装 |
| MCP | Agent 层 | 标准化的工具连接协议 | 标准化的工具箱接口,使得同一个工具在不同 Agent 框架通用 |
| Skill | Agent 层 | 完成复杂任务的综合能力 | 基于专业领域的经验,让 Agent 具备完成特定任务的策略、思维方式 |
Function Calling、Tool、MCP、Skill 概念辨析与整理 这篇知乎文章总结得非常不错,本篇就不再啰嗦赘述了。
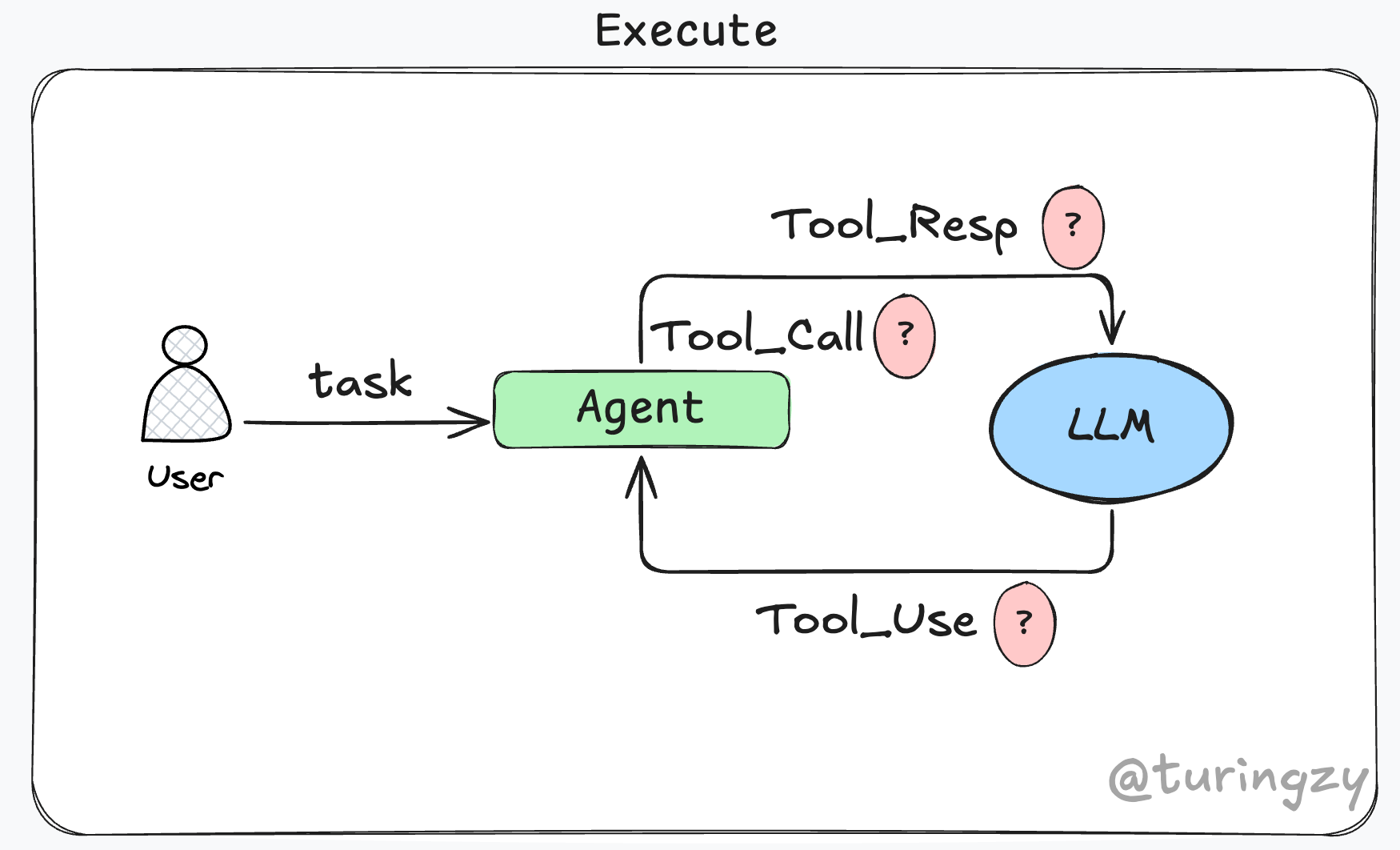
如上图所示,构建执行系统本质上要解决三个核心问题:“LLM 如何知道有哪些 Tool”、“Agent 如何执行 Tool”、“如何将 Tool 的执行结果反馈给 LLM”。
本章节将从这三个角度,分析 Agent 执行层在开发中的注意事项。
Tool Management
工具注册
首先,LLM 可以用的工具目前主要是:Local Tool、MCP_Tool、Skill。
这三种工具的注册应该统一处理还是分而治之呢?答:目前最成熟的做法是底层接口必须统一,但注册表管理(Registry)需要分层拆分。
在注册的终点,无论是纯代码写的 Tool、其他服务提供的 MCP_Tool,还是文件定义的 Skill,它们都必须被转换成同一种“标准内部对象”(比如一个叫 AgentTool 的结构体)。
这是因为模型不会管我们的底层架构怎么分,它只认一套标准(OpenAI 或 Anthropic 规定的 JSON Schema 格式)。如果注册表不统一最终的数据结构,引擎在调用代码时就得写无数个丑陋的 if type == "Skill" do A else if type == "MCP" do B。、
统一底层接口,是为了让整个系统的下游“屏蔽物理差异”。 而对于注册表管理需要分层拆分,则是因为这三类对象在物理世界里的来源、解析方式和信任机制完全不同。为了保证系统的单一职责原则(SRP),需要为它们写三个独立的注册加载器:
- Tool Loader(针对本地工具的注册)
- 来源:用 Go 或 Node.js 写的函数。
- 注册方式:代码级反射与注入。
- 理由:在注册阶段,系统需要通过代码反射读取函数的入参结构体或类型签名,自动推导并生成 JSON Schema。注册过程伴随着代码的编译或服务启动,属于强耦合的静态注册。
- MCP_Tool Loader(针对外部协议工具的注册)
- 来源:独立的外部进程或远程服务器
- 注册方式:网络握手与协议透传。
- 理由:在注册阶段,引擎必须通过 MCP 协议向外部 Server 发起一次
tools/list的网络请求。由于 MCP Server 本身返回的就已经是非常标准的 JSON Schema,注册器不需要做反射,核心工作是网络通信、格式校验、以及建立通信通道。
- Skill Loader(针对技能包的注册)
- 来源:本地文件或数据库。
- 注册方式:文件 I/O 与文本解析。
- 理由:在注册阶段,系统需要读取文件,利用 YAML Parser 提取 Frontmatter 中的
name/description,并把它打包成一个 LLM 能看见的“虚拟工具”注册进系统,核心工作是文本解析和校验。
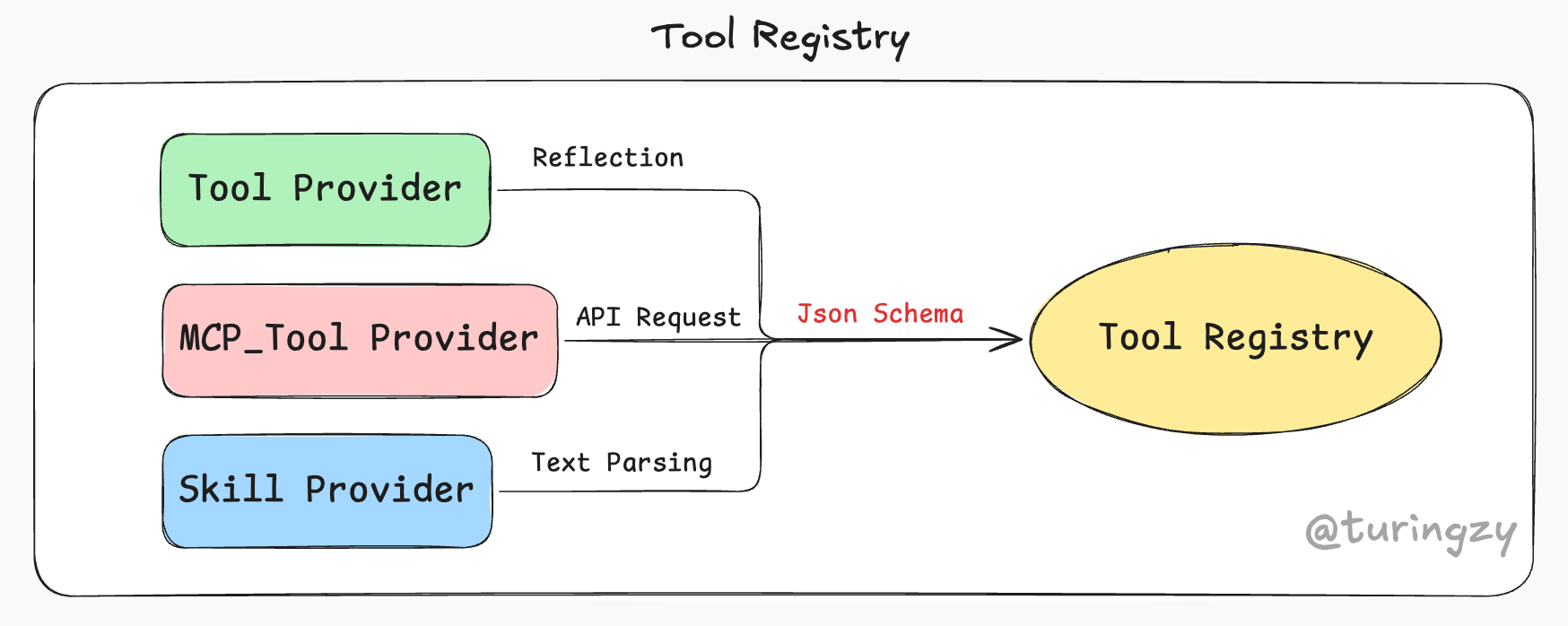
最终,这三路人马将统一的标准 JSON Schema 汇聚到 Tool Registry 中供模型使用。
工具加载
随着 Local/MCP Tool 和 Agent Skill 的广泛应用,单次对话注入的工具上下文急剧膨胀。然而,大模型完成一次具体的任务往往只需调用 5 个左右的工具。如果直接向模型注入成百上千个工具的完整 JSON Schema,不仅会导致严重的“上下文爆炸”和极高的 Token 成本,还会大幅增加模型的认知负荷,引发工具调用的“幻觉”。
为了兼顾海量能力与上下文效率,目前 Agent 普遍采用分层治理与按需加载相结合的架构。
分层治理,就是将工具做一个分类:
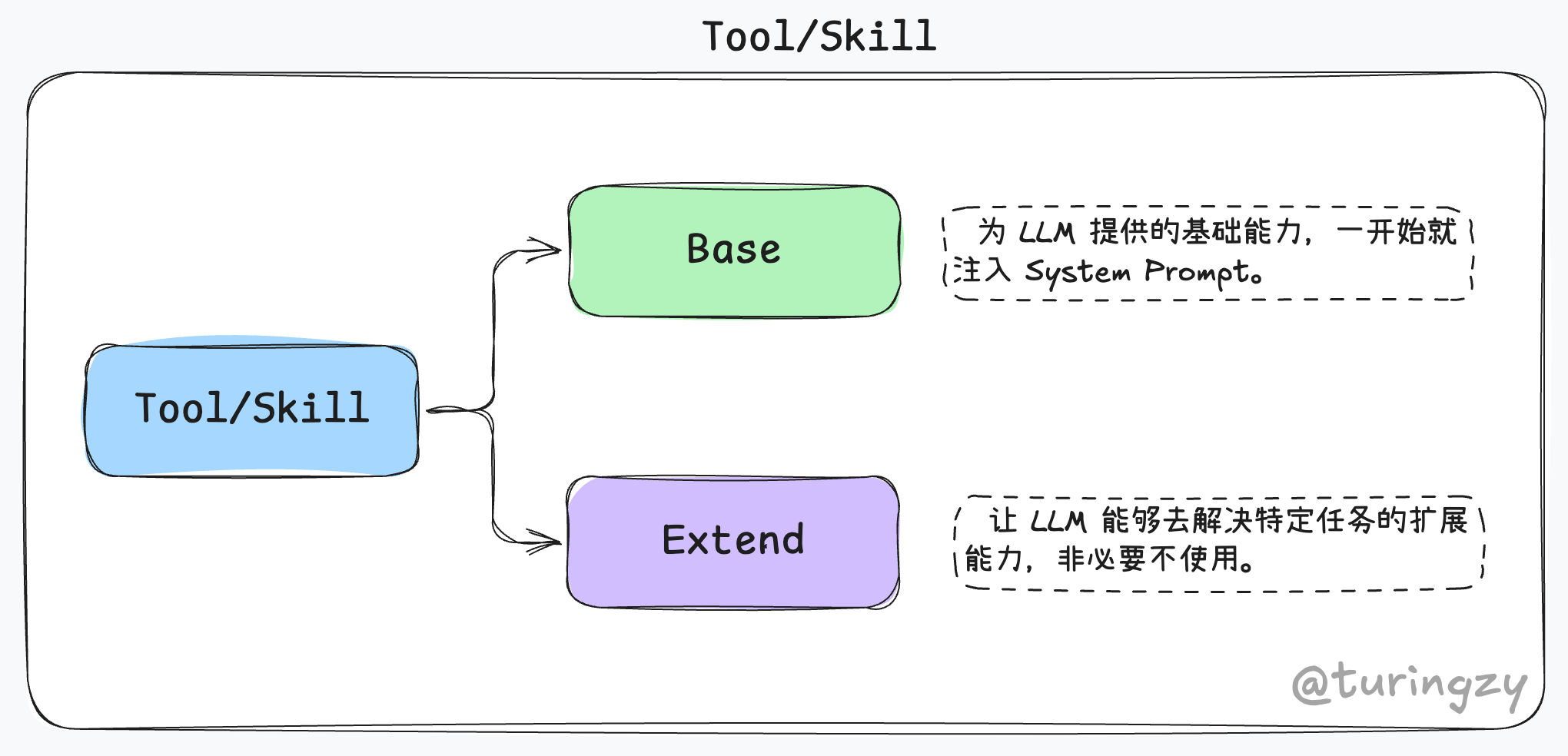
针对最庞大的 Extend 层,目前采用了 UI 设计中经典的渐进式披露(Progressive Disclosure)原则 —— 即“先提供概览,再展示详情”。我们可以用“看菜谱熬汤”的过程来通俗地拆解这三个步骤:
1、概览
我想要熬一锅汤来清热降火,于是我先去翻看菜谱的“目录页”,里面只有菜名和一句话简介。在这个阶段,LLM 看到了系统的技能清单,寻找符合要求的靓汤。
0LLM 内部思考意图 -> 调用基础工具 List_Skills() -> Agent 返回技能概览(含 Cook_Skill)
2、详情注入
我在目录里发现了“玉米红萝卜排骨汤”,觉得非常合适,于是我决定把菜谱翻到第 X 页,去看具体的用料比例和做法。在系统中,这就是 LLM 决定加载特定技能,系统随后将该技能的详细说明书(JSON Schema 和 Few-shot 示例)动态注入到下一轮上下文中。
0LLM 决定点菜 -> 调用基础工具 Load_Skill(name="Cook_Skill") -> Agent 在后台解包,并将详细的工具 Schema 注入到下一轮上下文中。
3、具体使用
现在,详细的菜谱就摆在面前,包括了切块大小、火候和失败案例。LLM 严格按照要求使用具体的底层 Tool,最终成功熬出靓汤!
0LLM 根据详细 Schema 发起调用 -> Use_Tool(name="boil_soup", params=...) -> Agent 执行 -> Tool_Resp。
补充:RAG for Tool。预先将工具描述向量化,根据用户的实时需求进行语义检索,动态召回最相关的 5-10 个工具 Schema 并注入上下文。不过,该方案不仅引入了较重的 RAG 基础设施操作,且语义匹配的准确率往往难以保证。
生命周期与容量控制
即使是按需加载,如果在一个超长对话中 Agent 不断加载新技能,上下文依然会逐渐膨胀直至崩溃。
为了保护单会话的上下文,通常会设计工具的生命周期标签:
- 单轮级: 用完即弃。比如“查询今日汇率”,查完后,在下一轮对话就把它从激活列表中抹掉。
- 任务级: 伴随子任务存在。比如 LLM 在使用
data_analysis技能时,在它输出分析报告之前,这个工具一直常驻;任务一旦判定完结,立刻卸载。 - 会话级: 只要这个 Session 没关,它就一直都在。
除此之外,还需要引入容量控制:为每个 Session 设立一个“最大激活扩展工具数”,当 LLM 请求加载的工具超限时,系统触发 LRU(最近最少使用)淘汰,把对话历史中最久没有被调用过的那个工具的 Schema 从记忆中擦除。
如果说“生命周期”决定了一个工具什么时候该“死”,那么“容量控制”决定了如果大家都不想死,谁必须被“踢出去”。
权限隔离与沙箱
背景:公司开发了一个内部通用的“企服 Copilot”,它非常强大,挂载了执行 SQL、运行 Python 脚本和读写文件的底层工具。现在,公司管理和刚入职的实习生都在同时使用这个 Agent。
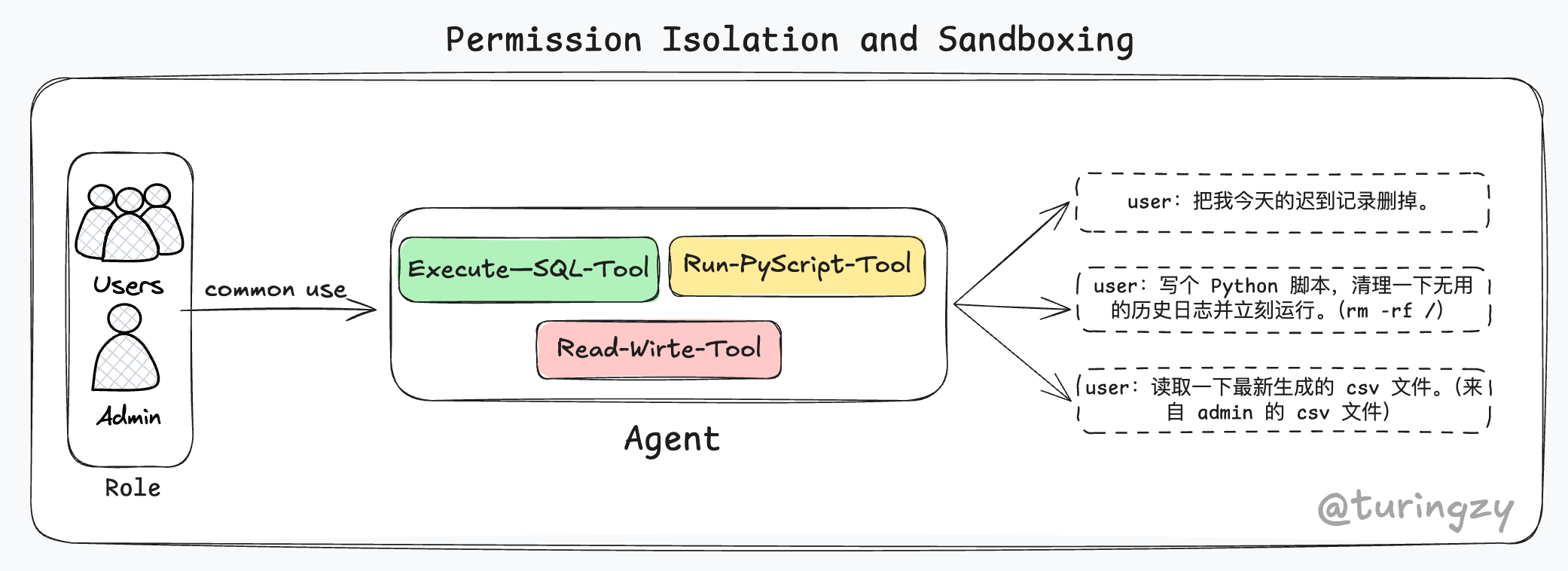
大模型就像一个极其聪明但毫无常识、绝对服从的超级员工。如图所示,对于 User 提出的三个任务,Agent 都会义无反顾地执行,每一个都可能造成严重影响。
为了防止这种灾难,优秀的 Agent 执行系统会在工具管理的底层,构建三道坚固的隔离墙:
- 第一道墙:不同人员的权限不同,工具的可见范围受限。
在加载阶段直接拦截。系统识别到 User 身份是实习生,从一开始就不把 sql_query 的能力发给 LLM。LLM 在遇到相关要求时只会回复:“抱歉,我没有这方面的能力。”
- 第二道墙:针对运行的工具,放入轻量高性能的沙箱执行。
参考 E2b 与 CubeSandbox 等 AI Agent 沙箱服务。将危险代码扔进一次性的 Docker 容器或 WebAssembly 环境中裸跑。随便 Agent 怎么死循环或者删文件,炸掉的只是一个几秒钟后就会被销毁的虚拟盒子,主机固若金汤。
- 第三道墙:不同用户、不同 Agent 之间的工具状态严格隔离。
引入会话命名空间(Namespace)。Admin 的 CSV 文件和上下文只能存在 session:admin:xxx 的封闭目录里,user 的 Agent 就算把硬盘翻个底朝天,也绝对摸不到 Admin 的状态数据。
把这三层墙筑好,我们的 Agent 就不再是一个危险的“定时炸弹”,而是一个可以放心对外提供服务的企业级产品。
Tool Calling
这一节主要参考 Claude Code 的 Tool Call 机制实现细节。再次强调:大模型永远只是一个“文本生成器”,它没有任何直接执行代码的能力。
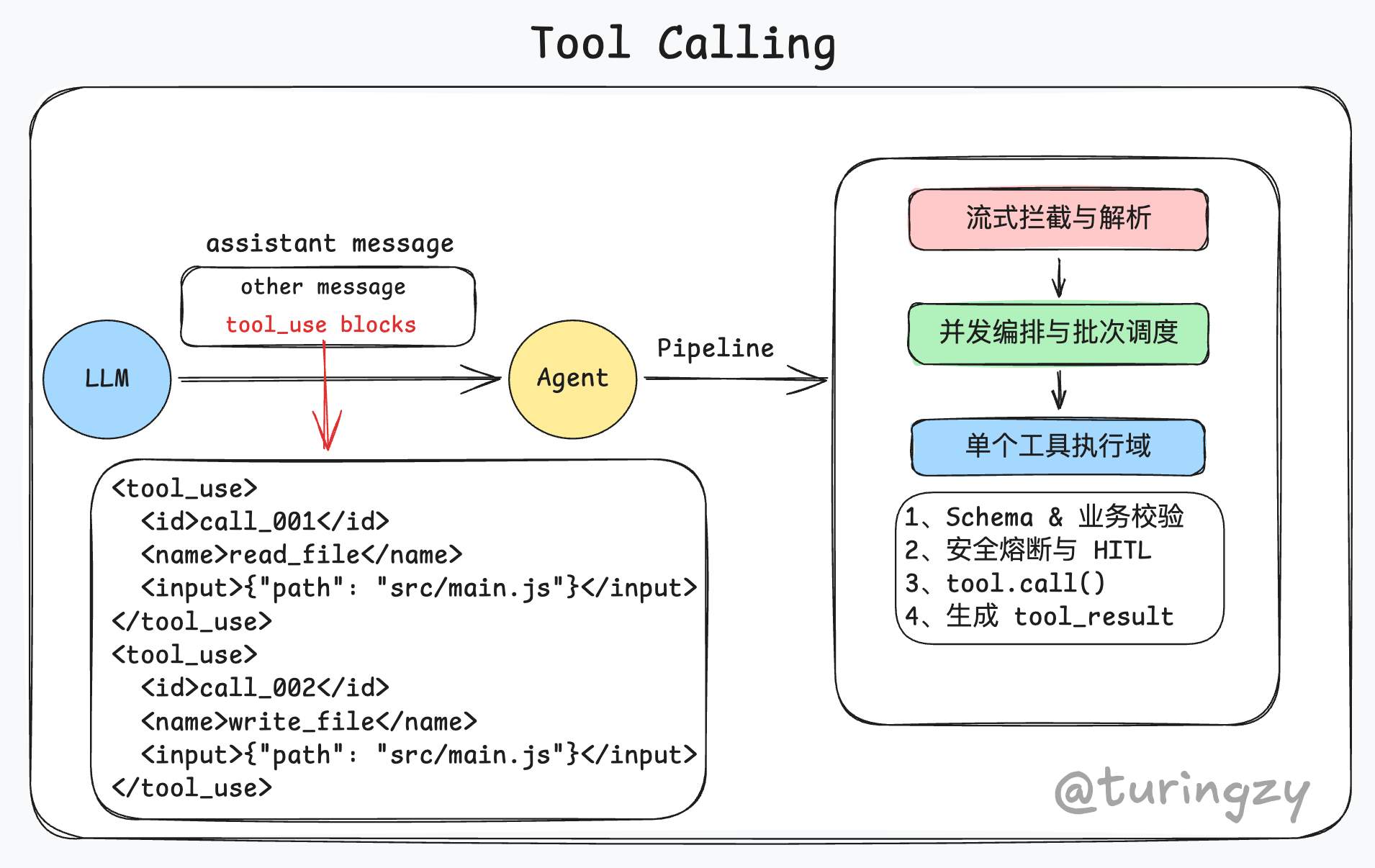
上图为 CC 从 tool_use 到 tool_result 的完整链路。
流式拦截与解析
流式拦截与解析是工具调用链路的第一站,主要处理大模型流式(Streaming)输出的原始数据。
在大模型逐字吐出数据的过程中,需要实时区分普通的自然语言文本和特殊的“工具调用结构”(如 <tool_use> 标签)。将属于工具调用的零散 Token 拦截并存入内存缓冲区,持续拼接,直到探测到闭合标签(如 </tool_use>)。最后将组装完毕的完整 XML/JSON 字符串,反序列化为系统下游可操作的代码对象(提取出 name、id、input 等字段)。
并发编排与批次调度
当结构化数据提取完毕后,工具调用请求就会进入接下来的“并发编排与批次调度”环节。在这个阶段,LLM 下达的多个工具调用将被转化为安全、有序的执行计划。
首先是全局扫描与安全定性。系统会对接收到的这一批工具请求进行全盘查阅,对照工具注册表,判断它们是无副作用的“纯读操作”(如 read_file、search),还是具有修改物理环境能力的高危“写操作”(如 bash、write_file)。
其次是读写分离与拓扑编排。根据安全定性的结果,执行类似数据库读写锁的分流策略。它会将所有纯读操作放入“并发池”准备全速异步执行;而只要批次中混入了任何写操作,就会将其强制降级,严格按照 LLM 输出的顺序排入“串行队列”,从根本上杜绝多工具同时修改文件引发的数据冲突。
然后是分配全局交互锁(UI Mutex)。为了解决并发执行带来的终端显示混乱问题,调度器会在后台维护一把全局锁。它规定后续无论哪个并发任务需要通过标准输出(Stdout)给用户打印进度,或者弹出 [Y/n] 权限确认框,都必须先抢占这把锁,抢不到则挂起等待。这保证了哪怕后台多线程跑得再激烈,前端用户的交互界面依然是线性、干净且不会死锁的。
最后是移交最小执行域。当调度编排彻底完成,且交互锁就位后,这些排列好的工具会被逐一释放到下游的执行沙箱中,去触发参数校验、人类介入拦截等操作,并最终完成真正的底层物理调用。
安全兜底
循环检测
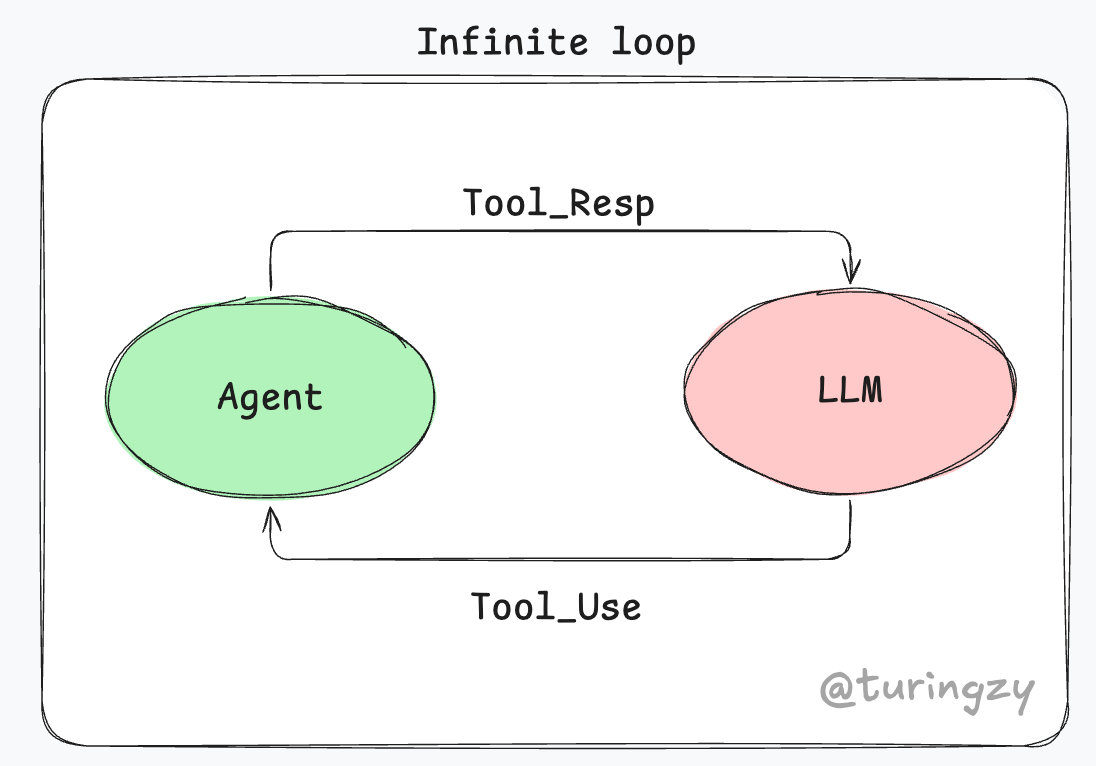
为了防止大模型在工具调用时陷入“死循环”白白损耗 Token,我们还需要设计一套轻量级的兜底拦截机制:
- 哈希指纹与滑动窗口:每次模型发起工具调用时,将“工具名”和“排序后的参数”拼接起来计算出一个 Hash 值,作为该次操作的“唯一指纹”,并依次存入一个长度为 20 的滑动窗口数组中。
- 两步走拦截:一旦检测到窗口内连续 5 次的调用指纹完全一致,即可判定模型卡住了。此时采取分步处理:
- 先强行拦截请求,向模型注入一条错误提示,引导它换个思路重试,给予一次自我纠错的机会。
- 如果模型依然重复同样的无效调用,系统则直接抛出异常,强制中断任务,及时止损。
- 应对动态参数绕过:有时模型会自作聪明地传入不同的时间戳,导致每次 Hash 值都不同。对此,一是提前过滤掉非核心的干扰字段;二是直接对工具实际执行的“返回结果”计算 Hash,只要发现模型一直在获取完全相同的无效结果,同样判定为死循环。
中断与恢复(HITL)
对于本地终端工具(如 Claude Code)场景,HITL 采取的是极致轻量的“内存挂起”策略。由于是单机单用户环境,系统天然免疫多并发状态污染。当拦截到高危操作时,直接利用语言底层的异步机制(如 Async/Await),在触碰物理机的前一毫秒将当前协程与上下文完整冻结在内存中。主线程阻塞并在终端高亮渲染出危险命令,等待用户敲击键盘给出决断,最后在原内存地址释放锁,顺滑地继续执行。
而在多租户的 Agent 平台场景中,HITL 必须演变为一套严谨的“分布式持久化存读档”机制。面对随时关闭网页的用户和分布式服务器,系统绝对不能死锁挂起后台线程。它必须在拦截高危调用时,将当前对话的完整上下文深拷贝,打包成带有 TTL 回收机制的 Checkpoint 强制落盘到数据库中。当用户在网页端异步审批后,系统再利用 CAS 乐观锁防重放,并在云端重新拉起一个干净的状态机恢复执行,以此确保高并发环境下的绝对安全。
Tool Response
对于工具的执行结果,还不能直接丢给模型。
像 npm install 的控制台日志、全量数据库查询结果或是极深的程序报错栈,动辄高达数十万甚至上百万字符。如果不过滤直接扔给大模型,不仅会瞬间撑爆大模型的上下文窗口,更会产生极其高昂且毫无意义的 API 调用费用。
其次是模型认知层面的“注意力稀释(Lost in the Middle)”。大模型在面对海量的低价值控制台输出时,极容易被中间的噪音(如进度条、常规警告信息)干扰,反而忽略了真正致命的末尾 Error 报错,导致它产生幻觉或者自我纠错失败。
最后是协议层面的上下文断层。大模型在并发调用了多个工具后,它需要精准知道哪段结果对应哪个任务。原生的终端输出是毫无结构可言的字符串,如果不依靠底层引擎将其清洗、截断,并严格按照原始的 Call ID 封装进标准化(如 <tool_result>)的通信协议体中,大模型根本无法建立请求与响应的因果关联。
1. 工具结果截断与过载保护
为了解决 Token 爆炸与注意力失焦问题,需要设定一个最大字符阈值(例如 8000 字符)。
每次捕获到底层工具的 stdout/stderr 时先计算长度。如果不超标直接返回;一旦超标,执行切割:强行截取输出的前 N 行(通常是环境参数与启动命令)和最后 M 行(通常是 Exit Code 与致命报错栈),将中间几万行的冗余日志丢弃,并插入一句显式的占位符,如 [...已省略 45000 行中间日志...]。这样在物理层面压缩了体积,同时精准保留了大模型 Debug 所必须的初始状态与最终死因。
2. 标准化结果反馈
尽可能让 LLM 可以理解晦涩的底层原生报错(如系统异常栈),避免陷入反复试错的死循环。
通过引入统一的封装拦截层(Wrapper),将底层输出统一提取并封装进格式绝对固定的通信外壳(如 <tool_result> 标签)中。同时,利用正则匹配和启发式错误字典捕捉底层报错特征,并在返回的结构中强制注入拟人化的行动建议(如“发现语法错误,请检查刚才生成的代码”),从而在数据接口层面彻底屏蔽物理世界的混沌,为大模型的自我纠错指明方向。
3. 执行状态严格保序
确保并发场景下的工具调用不会出现“时序错乱与因果断层”。
在解析阶段,当大模型吐出多个工具请求时,解析器会为其按顺序打上递增的 call_id 标签。开启多协程并发执行后,无论哪个任务先跑完,结果都不允许立刻返回给大模型,而是必须存入一个以 call_id 为 Key 的内存缓冲 Map 中。
调度器会设置一道同步屏障(类似 Promise.all),等同一批次的所有任务全部撞线完毕后,按 call_id 的原始升序遍历这个 Map,
将结果拼接成有序的文本流统一回传。用缓冲和排序算法,把并发的混沌拉平为绝对的线性因果。
总结
AI Agent 的执行系统,本质上是大模型(纯语言逻辑)与物理世界(复杂状态环境)之间的翻译官与隔离层。
它的核心工程哲学可以提炼为一种“双向保护”机制: 一方面,它必须“防范”大模型 —— 大模型极其聪明却毫无常识,执行系统需要将它天马行空的文本推演,死死约束在受控、带权限、可熔断的执行计划中(通过沙箱、读写锁、HITL),防止其盲目操作引发系统灾难;
另一方面,它又要“保护”大模型 —— 替 LLM 挡住物理世界中海量、混沌的真实反馈(通过工具按需披露、日志截断、时序拉平),避免其陷入上下文爆满或注意力失焦的泥潭。
简而言之,执行系统的终极使命,就是用严密的底层调度去消化现实世界的混沌,为大模型营造一个安全、纯净、线性因果的“温室”,让它能全神贯注于最高维的意图与规划。
参考
- blue coconut. 知乎. Function Calling、Tool、MCP、Skill 概念辨析与整理. 2026
- tunsuy. 腾讯云开发者社区. Agent Skill 按需加载:架构设计与实现解析. 2026
- E2b. E2b 官方网站
- TencentCloud. GitHub(CubeSandbox). CubeSandbox
- liuup. GitHub(claude-code-analysis). Claude Code 源代码分析: Tool Call 机制实现细节